

0x00 《文字游戏》真结局
1 月 25 号看到 B 站上关于《文字游戏》的视频:只有中华文化圈内人才能玩明白的游戏 - bilibili,感觉很有意思,于是上 steam 买了。游戏时间大概 6h,打出了一个真结局。
游戏前五章的情节是典型的「勇者打恶龙救公主」,但后续情节来了个大反转。具体就不说了,总之这 40+ CNY 还是很值的。我打出的真结局是 5 号结局,游戏结束之后发现桌面生成了一个叫做 MINDTYPER 的文件夹(游戏中文本编辑器软件的名字),里面有两个文本文件 v4398.txt 和 起点.txt,彩蛋就隐藏在后者。
(三月九日)
今天去了医院。
医生说我康复的状况非常好,活动力和语言能力都已经回到了正常水平,之后不用再回诊了。
・
(四月十九日)
妈最喜欢的那一株玫瑰花开了。
・
(五月十一日)
又把你的稿件从头到尾读了一遍。
他们很棒,没有一个字是狗屁。
感谢小帮手保存了你的一切,让我能再次认识许多曾经认识的人,也参与那些我已经来不及参与的事。
我又去了那片草地。就跟小时候你带我来的那天一模一样,仿佛时间从来不曾离去。蓝天清朗如画布稿纸,白云恣意地书写文字,你在暖阳底下陪着我游戏。好想回到那天,亲口对你说一声谢谢。
勇者和公主会一直活在你的文字里,在诗人的带领下完成一篇一篇动人的故事。如果你在某一个我不能抵达的时空读到,请不要埋怨我将某一个版本的尾声弄得过于圆满。
我喜欢这个故事,希望你也喜欢这个《文字游戏》。
人人人人人人人人人人人人人人人人人人人人人人人人人人……
人人人人人人人人人人人人人人人人人人人人人人人人人人……
人人人人人人人人人人人人人人人人人人人人人人人人人人……
人人人人人人人人人人人人人人人人人人人人人人人人人人……
……这个 txt 文件的大小高达 182KB,几乎肯定有字符画。利用记事本自带的缩放功能可以看个大概。但是行距过大,看不太清楚。因此笔者想到用 Python 来绘制这幅字符画。
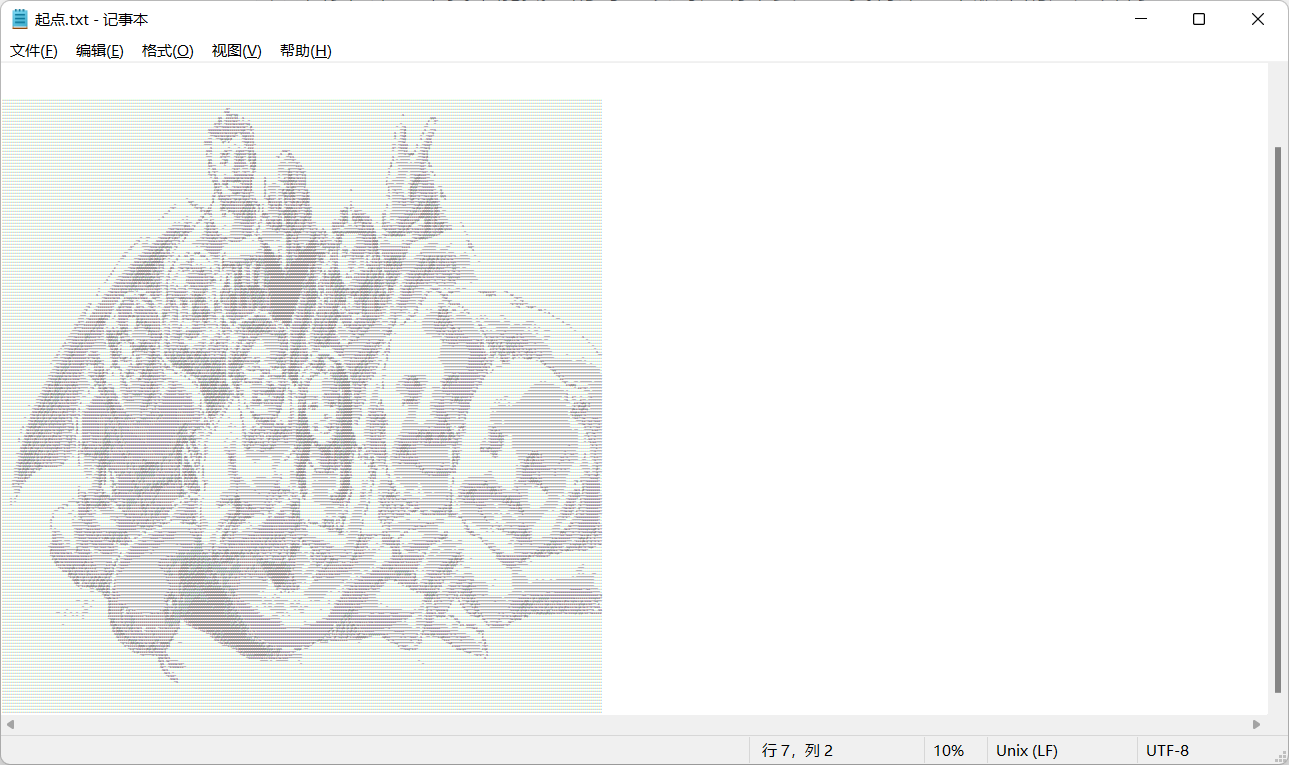
起点.txt 字符画彩蛋,记事本软件 10% 缩放0x01 绘图
要绘制字符画还算是很简单的工作。图里面只有「我」「人」「文」「字」「遊」「戲」这 6 种字符,只需要生成这 6 种字符的图形,然后拼接起来。
不过生成图形的过程中发生了一点小意外。本来笔者以为中文字都是方形的,但是绘制一下:
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
font = ImageFont.truetype('C:\Windows\Fonts\SourceHanSerifCN-Regular.otf', 32)
image = Image.new('RGB', (64, 64), 'white')
draw = ImageDraw.Draw(image)
draw.text((0, 0), '文', 0, font)
plt.imshow(image)
plt.show()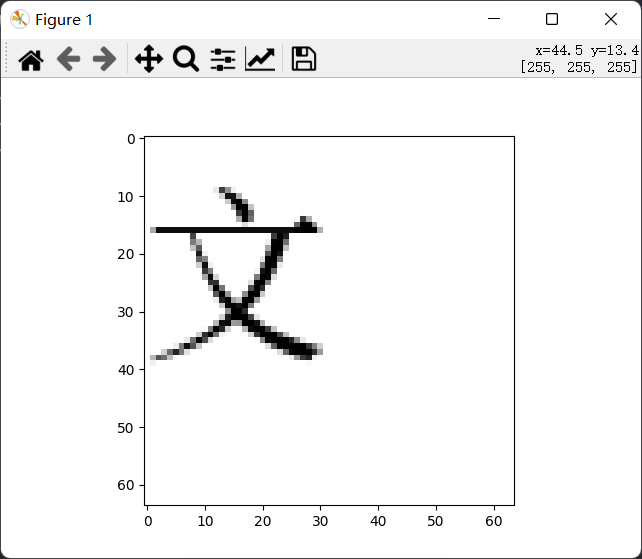
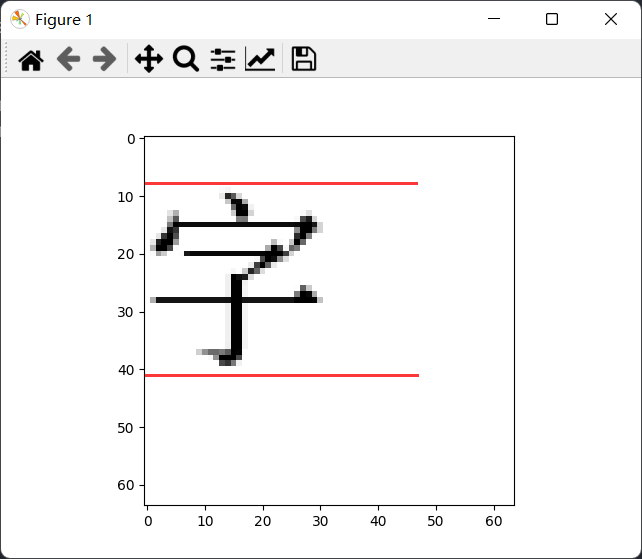
反转了,即使指定在 (0, 0) 处绘制,文字上方仍然存有大量空白。查阅资料:

原来汉字的 box 并非正方形。于是将生成出来的图片裁剪成 32 × 32,最终代码如下:
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
from functools import lru_cache
font_size = 32
font = ImageFont.truetype('C:\Windows\Fonts\SourceHanSerifCN-Regular.otf', font_size)
@lru_cache(10)
def get_image(ch):
w, h = font.getsize(ch)
print(w, h)
image = Image.new('RGB', (w, h), 'white')
draw = ImageDraw.Draw(image)
draw.text((0, 0), ch, 0, font)
return image.crop((0, h - font_size, font_size, h))
text = open('text.txt', encoding='utf8').read().split()
def draw_photo(text):
target = Image.new('RGB', [font_size * len(text[0]), font_size * len(text)])
for pos_row, row in enumerate(text):
for pos_col, ch in enumerate(row):
target.paste(get_image(ch), [pos_col * font_size, pos_row * font_size])
return target
output = draw_photo(text)
plt.imshow(output)
plt.show()
output.save('out.png') 代码没什么好说的。给 get_image 函数施加了一个 @lru_cache 装饰器,来避免重复绘制字符图像。此外,paste 的时候需要注意 box 参数是 (left, upper) ,所以需要先列、后行指定坐标。
尝试了两种不同的字体,分别是更纱黑体(Sarasa Fixed SC Regular)和思源宋体(Source Han Serif CN Regular)。效果如下:


读者可以放大上面的图片,能明显地看到中文字符。两种字体最终呈现的差异,主要是更纱黑体颜色更深、有更高的对比度。原始文件可以在这里下载:
做完了绘图工作之后,笔者开始考虑「如何从图像生成这样的字符画」。在 Linux 下,我们常常使用的 screenfetch、neofetch 就有这样的字符画:
╭─root@raspberrypi ~
╰─# neofetch
_,met$$$$$gg. root@raspberrypi
,g$$$$$$$$$$$$$$$P. ----------------
,g$$P" """Y$$.". OS: Debian GNU/Linux 11 (bullseye) aarch64
,$$P' `$$$. Host: Raspberry Pi 4 Model B Rev 1.1
',$$P ,ggs. `$$b: Kernel: 5.10.63-v8+
`d$$' ,$P"' . $$$ Uptime: 40 days, 3 hours, 52 mins
$$P d$' , $$P Packages: 1630 (dpkg)
$$: $$. - ,d$$' Shell: zsh 5.8
$$; Y$b._ _,d$P' Theme: Adwaita [GTK3]
Y$$. `.`"Y$$$$P"' Icons: Adwaita [GTK3]
`$$b "-.__ Terminal: /dev/pts/0
`Y$$ CPU: BCM2835 (4) @ 1.500GHz
`Y$$. Memory: 272MiB / 3795MiB
`$$b.
`Y$$b.
`"Y$b._
`"""
那么,应该从哪里做起?笔者选择首先做出一个「灰度图 → 字符画」的转换算法,然后再设计上色的算法。
0x02 灰度图 → 字符画
参考《文字游戏》彩蛋的设计,我们只采用若干个中文字符(以及空白)来完成字符画。程序的输入是一个 $n \times m$ 的灰度图,以及缩放参数 $k$,我们的算法将原图切成每份 $k\times k$ 的小块,对每个小块用最近似的字符来替代。
稍微有几个细节需要考虑。首先,原图的长、宽不一定就是 $k$ 的倍数,所以需要做一点裁剪。其次,关于如何把 RGB 图像转为灰度图,我们先来尝试两种办法。第一种是 Gray = (R+G+B) / 3 ,第二种是 Gray = R*0.299 + G*0.587 + B*0.114。它们的效果如下:



显然第二种方法转换效果更好。所以接下来采用第二种转换方法来进行 RGB to Grayscale。现在我们面临的问题是:既然我们使用一个字来表示原图中的一个 $k\times k$ 块,那么如何决定采用哪个字符?
笔者首先想到采用 MSE Loss,将字符的 $k\times k$ 图形与块进行比较,求 MSE Loss,loss 值最低的胜出。然而,事实证明这样的方案结果很差,尤其在 $k$ 较大时:
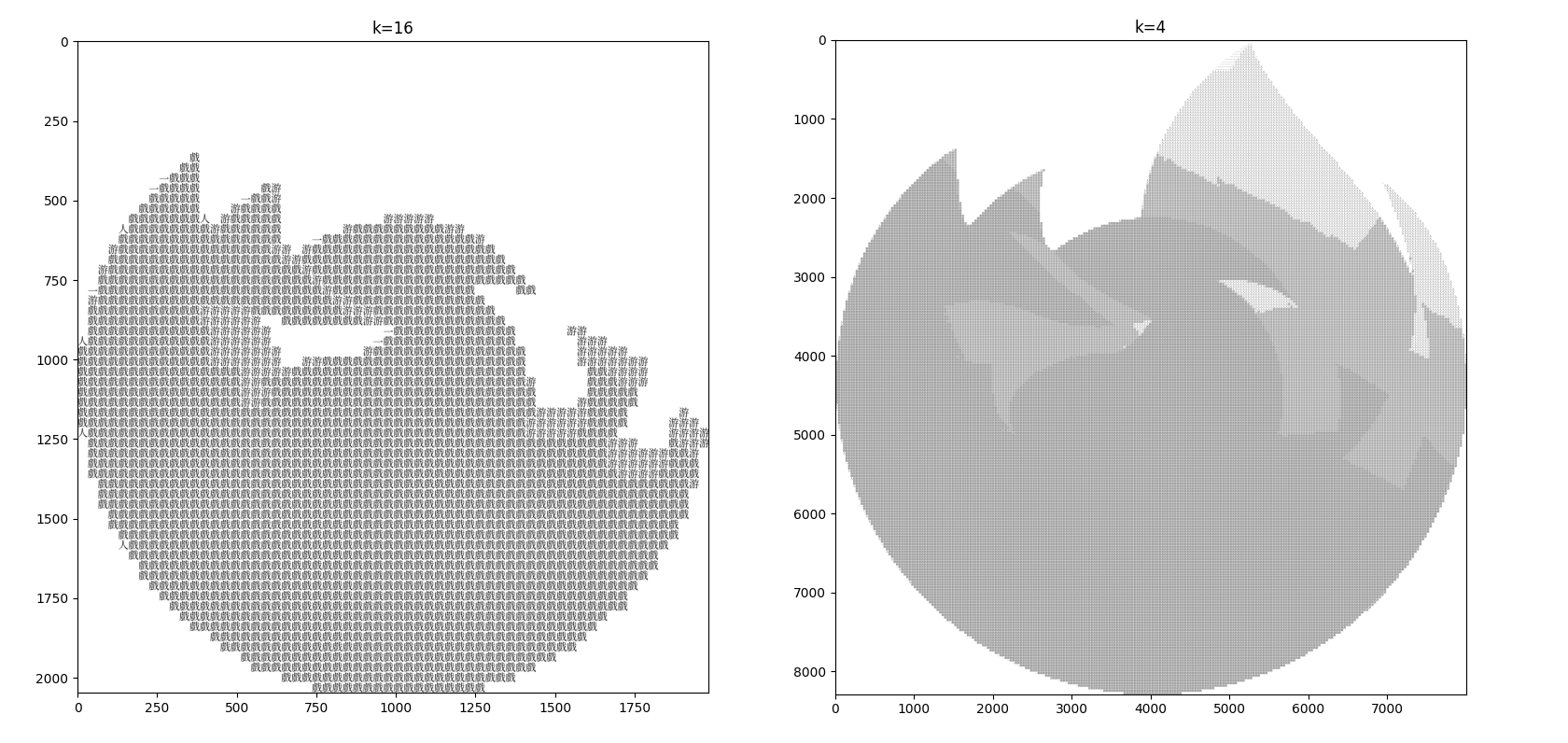
思考之后发现,MSE Loss 衡量的是每个 dimension 之间的差异。在本任务中,那就是「A 的第一个像素与 B 的第一个像素、A 的第二个像素与 B 的第二个像素……」的差异。这样的话,如果 B 是 A 的平移,MSE Loss 会非常大,然而事实上我们肉眼认为 A 与 B 很相似。
所以我们需要换一种衡量方法。考虑「字符的平均灰度与图片块的平均灰度」差异,另外对图片进行淡化处理。生成结果如下($k$ 均取 4):
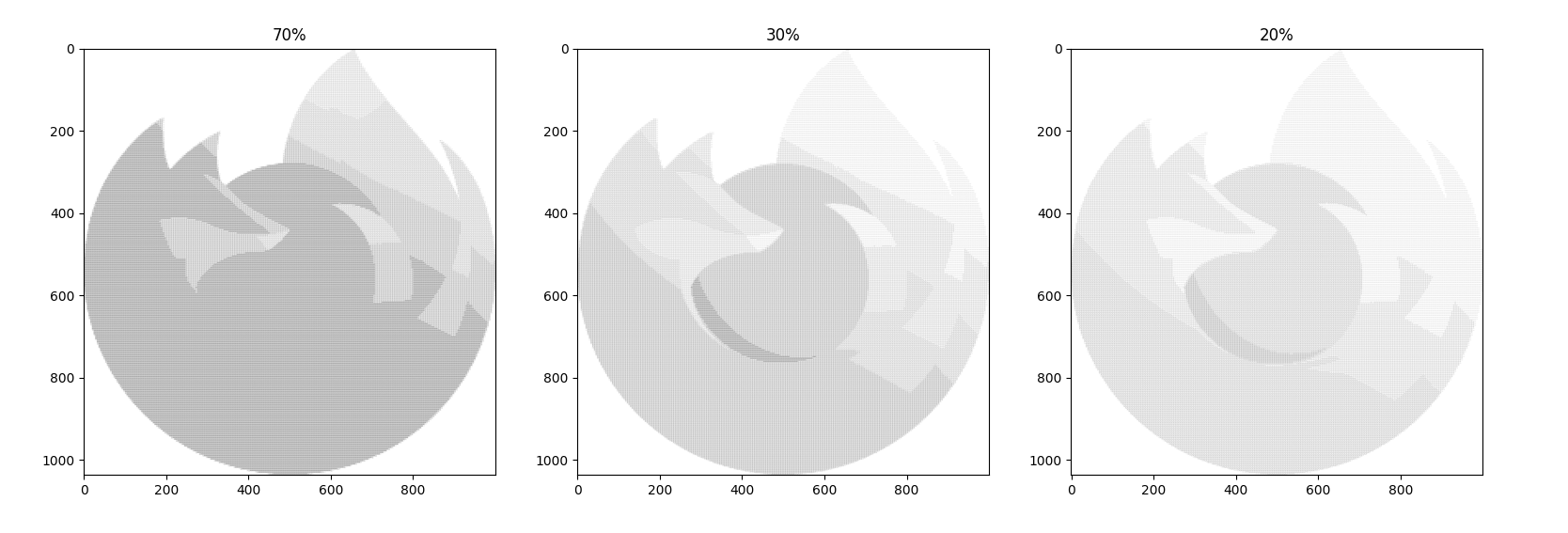
可见对于这张 Firefox logo,保留 30% 黑色是较好的选择。来点二次元:


0x03 上色
由于现代终端很容易操控字符颜色(Python 有 colorama 库用于这个操作),浏览器也原生支持各种颜色的文字,我们可以构造一些带颜色的字符画。虽然终端支持的颜色很少,但我们这里先假装 RGB8 范围内的颜色都可用。
一个小块转化成一个字符之后,显然这个字符的颜色最好是原来图块颜色的均值。我们很容易写出代码。效果如下:




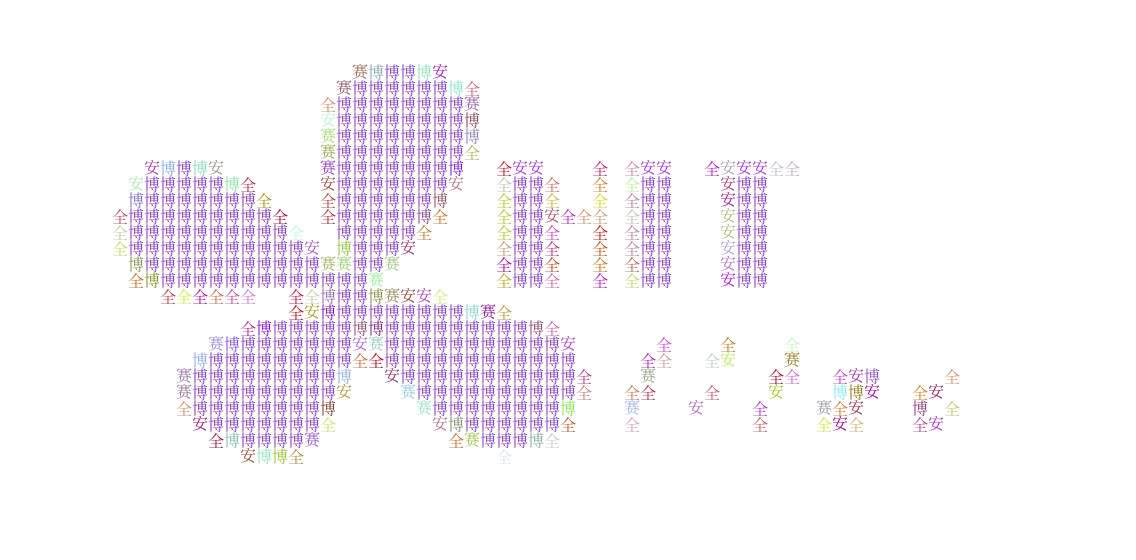
在画百鬼大小姐的时候出现了非常明显的问题。请看:



大小姐身边的那几条小鬼是蓝紫色的,但在生成出的图片里面变成了红绿色的。为啥?笔者又因为学艺不精犯了个比较低级的错误:「原来图块颜色的算术平均值」不应该用于描述原图颜色。举个简单的例子,如果在原图中有一个图块,一半像素是紫色 #9999FF,其余的空间是白色,那么在平均之后,会变成 #CCCCFF,凭空变淡了,如下图所示。取算术平均值时,各种颜色会混在一起,最终的效果是很差的。
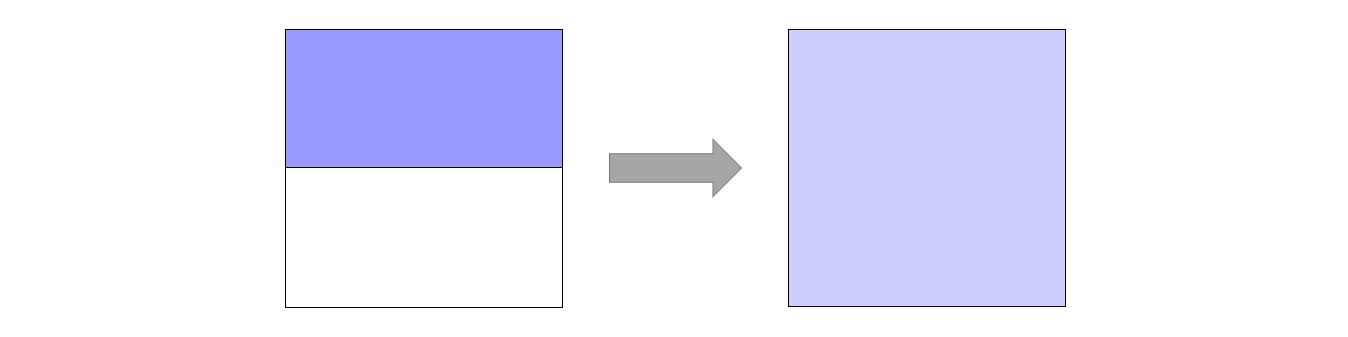
所以,取原图块的平均色值是个很烂的办法。我们马上可以想到,取原块的最左上角像素颜色。现在出来的图片就正常很多了:



$k=4$ 的时候,已经非常清晰了。下图没有做淡化处理,左边是更纱黑体(bold),右边是思源宋体。


用新算法重新生成一下 Firefox 的 logo:


可见比最初合理多了。下面是源码:
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
import numpy as np
from functools import lru_cache
k = 16
font = ImageFont.truetype('C:\Windows\Fonts\SourceHanSerifCN-Regular.otf', k)
@lru_cache(100)
def get_image(ch):
w, h = font.getsize(ch)
image = Image.new('L', (w, h), 'white')
draw = ImageDraw.Draw(image)
draw.text((0, 0), ch, 0, font)
res = image.crop((0, h - k, k, h))
assert (res.width, res.height) == (k, k)
return np.array(res, dtype=float)
char_list = [' ', '百', '鬼', 'あ', 'や', 'め', ]
char_image = {x: get_image(x) for x in char_list}
def rgb_to_gray(arr):
return (0.299 * arr[:, :, 0] + 0.587 * arr[:, :, 1] + 0.114 * arr[:, :, 2])
img = np.array(Image.open('ayame.png'), dtype=float)[:, :, :3]
gray = rgb_to_gray(img)
paint_height, paint_width = gray.shape[0] // k, gray.shape[1] // k
gray = gray[:paint_height * k, :paint_width * k]
print(gray.shape, paint_height, paint_width)
# print(gray)
def get_slice(img, row, col):
return img[col * k: (col + 1) * k, row * k: (row + 1) * k]
def loss_fn(x, y):
# print(x.shape, y.shape)
correlated = 255 * k * k - (255 * k * k - np.sum(x.reshape(-1))) * 1.0
return np.abs(correlated - np.sum(y.reshape(-1)))
# plt.imshow(get_slice(gray, 10, 10), cmap='gray')
# plt.show()
# paint_height = 10
# paint_width = 10
output = []
def get_color(img):
r, g, b = img[0, 0, 0], img[0, 0, 1], img[0, 0, 2]
return int(int(r * 256 * 256) + int(g * 256) + int(b))
for col in range(paint_height):
for row in range(paint_width):
cur, res = 0xffffffff, 'X'
for x, y in char_image.items():
loss = loss_fn(get_slice(gray, row, col), y)
if loss < cur:
res, cur = x, loss
output.append([res, get_color(get_slice(img, row, col))])
print(output)
# with open('ayame.txt', 'w', encoding='utf8') as f:
# for row in np.array(output).reshape([paint_height, paint_width]):
# f.write(''.join(row))
# f.write('\n')
def draw_color_text(ch, color):
w, h = font.getsize(ch)
image = Image.new('RGB', (w, h), 'white')
draw = ImageDraw.Draw(image)
draw.text((0, 0), ch, color, font)
res = image.crop((0, h - k, k, h))
assert (res.width, res.height) == (k, k)
return res
def draw_photo(text):
target = Image.new('RGB', [k * len(text[0]), k * len(text)])
for pos_row, row in enumerate(text):
for pos_col, ch in enumerate(row):
# print(hex(int(ch[1])))
piece = draw_color_text(ch[0], '#' + hex(int(ch[1])).replace('0x', '').rjust(6, '0'))
target.paste(piece, (pos_col * k, pos_row * k,))
return target
ans = draw_photo(np.array(output).reshape([paint_height, paint_width, 2]))
# plt.imshow(ans)
# plt.show()
ans.save(f'ayame-k{k}.png')