

0x01 背景
笔者最近在尝试使用 STM8 开发板去控制一个 WS2812B LED。我们知道,RGB LED 一般有两种:一种是三个引脚分别接 R、G、B 三色的 LED,这是最简单的,ESP8266「机智云」开发板即搭载了这种 LED,三个 IO 口各自进行 PWM 就可以控制。但它的坏处在于浪费引脚:很多 MCU 的 PWM 引脚有限,若需要控制 LED 矩阵,几乎毫无办法。另一种 RGB LED 是通过协议来控制,例如 WS2812B,除了电源接口 VCC、GND 以外,设有 DIN、DOUT 接口,传输 RGB 信息。
WS2812B 被设计得很容易串联。我们需要 24bit 的信息(即 RGB8 值)去控制一颗 LED,而每次传输信息时,LED 获取自己的 24bit 操控信息,并将剩余的包原样发给下一颗 LED。如 datasheet 所给的例子:
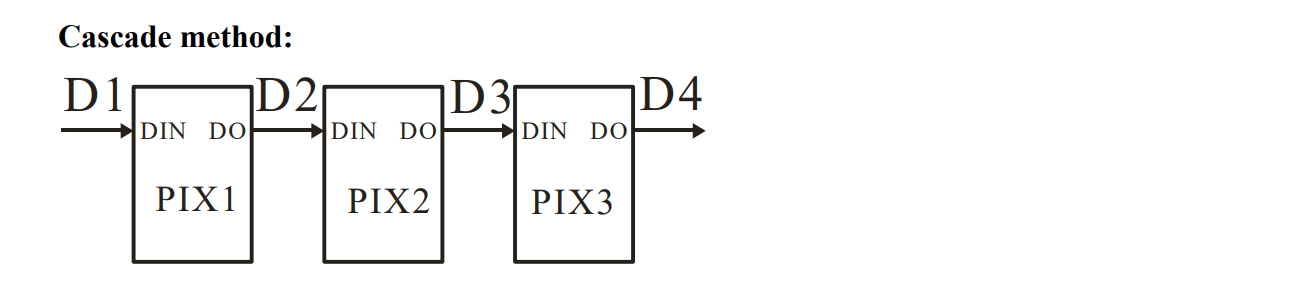
这里串联了三个 LED,每个 LED 截取自己的信息,并将剩余的报文从 DOUT 输出。
0x02 寻找现有库
正经 Arduino 开发板上的 MCU(例如 Arduino UNO R3 所搭载的 ATmega328P),以及 ESP8266、ESP32 可以方便地使用 Adafruit NeoPixel 包:
然而,这个库不支持 STM8。在网络上又找了一些其他的声称支持 STM8 的库:
然而都在编译期间失败了。笔者的开发平台是 PlatformIO,首先会因为 PlatformIO Arduino 框架所使用的编译器不支持 --less-pedantic 开关而报错。这倒是容易解决,修改 .platformio\platforms\ststm8\builder\frameworks\arduino.py 的第 52 行,注释掉这个开关:
env.Append(
CCFLAGS=[
# "--less-pedantic"
],
# ...
)然而还有些其他问题,笔者尝试了一些方法,不能解决。STM8 确实小众,不像 ESP8266 那样有各种 Arduino 包。笔者决定自己实现这个任务。
0x03 时序分析
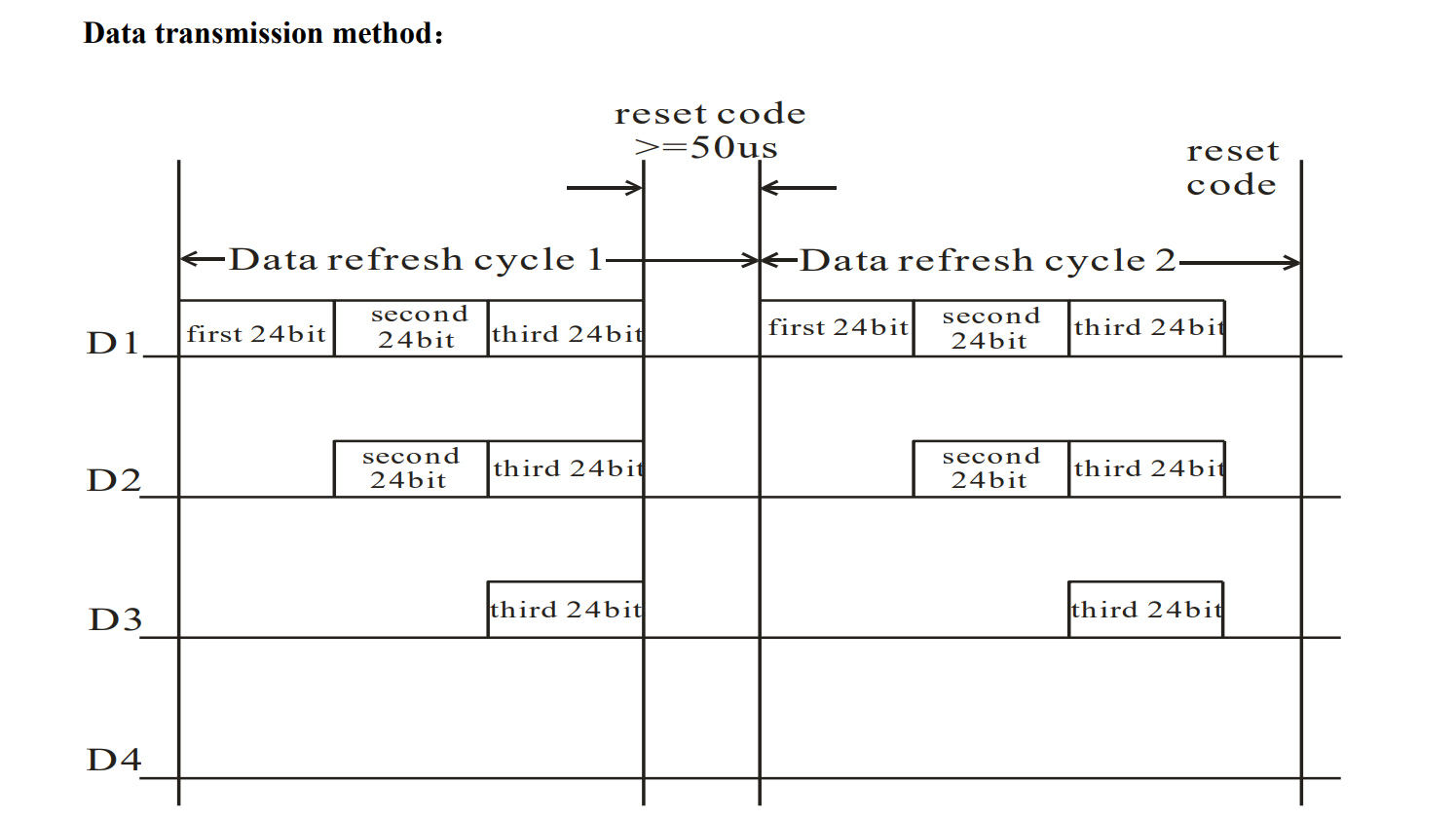
每 24bit 信息用于控制一个 LED,对于 $n$ 个 LED 串联的灯组,我们需要连续发送 $n\times 24$ 个 bit 构成的报文。两个报文之间间隔至少 50us。每传输一个 bit 用时约为 1.25us,传输 24bit 需要 30us。因此我们马上可以进行理论计算:
- 控制单个 LED,每条报文传输时间(含 50us 的间隔)是 80us,理论最高刷新率是 1000000 / 80 = 12500Hz
- 控制 $10\times 10$ 的 LED 矩阵,每条报文传输时间是 3050us,理论最高刷新率 327Hz
- 控制 $1024\times 768 = 786432$ 个 LED,每条报文传输时间约 23.6s,理论最高刷新率约为 0.04Hz
datasheet 说对于 1024 个串联的 LED 可以做到 30fps,很接近我们的理论计算值 32.5 fps。理论传输速度是 1000000/1.25 = 800kbps。不过本文只考虑控制单个 LED。
来看具体的通讯时序要求。每个 bit 的发送规则如下:
- 发送 0:拉高 400ns,拉低 850ns。各允许 $\pm$150ns 的误差。
- 发送 1:拉高 800ns,拉低 450ns。各允许 $\pm$150ns 的误差。
我们可以通过 delayMicroseconds() 来做 us 级的延时,然而控制 WS2812B 需要把延时粒度进一步降低到数十 ns 级。此外, digitalWrite 并不是很快,我们可以用以下代码测试一下:
while(1) {
digitalWrite(LED_PIN, 0);
digitalWrite(LED_PIN, 1);
}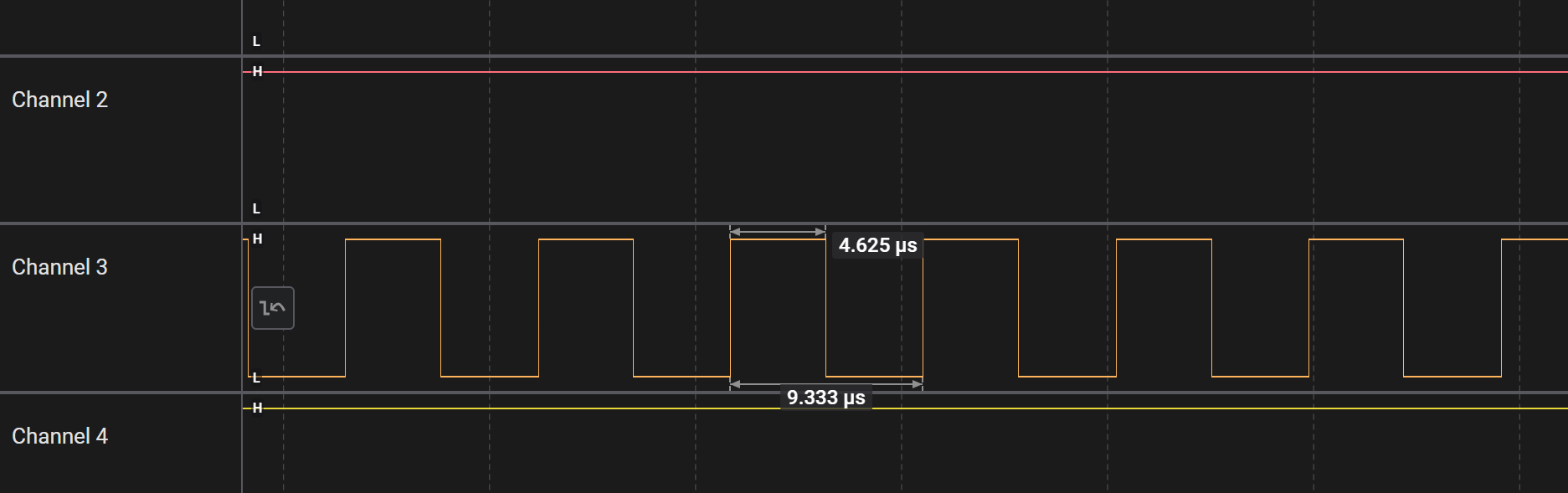
高、低电平各持续 4.6~4.7us,显然无法达到本任务的时序要求。看一眼 digitalWrite 的源码:
void digitalWrite(uint8_t pin, uint8_t val)
{
uint8_t timer = digitalPinToTimer(pin);
uint8_t bit = digitalPinToBitMask(pin);
uint8_t port = digitalPinToPort(pin);
volatile uint8_t *out;
if (port == NOT_A_PIN) return;
// If the pin that support PWM output, we need to turn it off
// before doing a digital write.
if (timer != NOT_ON_TIMER) turnOffPWM(timer);
out = portOutputRegister(port);
BEGIN_CRITICAL
if (val == LOW) {
*out &= ~bit;
} else {
*out |= bit;
}
END_CRITICAL
} 编译出的汇编码更是有 60 行,因此 digitalWrite 是指望不上了,我们需要直接操纵寄存器,来实现拉高和拉低电平,而且延时也需要使用 nop 实现。
0x04 编程
笔者手上这块 STM8 是 STM8S103F3P6,主频 16MHz。理论上来讲,一个时钟周期是 62.5ns。实际测试一下,我们写 1000 个 nop 指令,看看耗时:
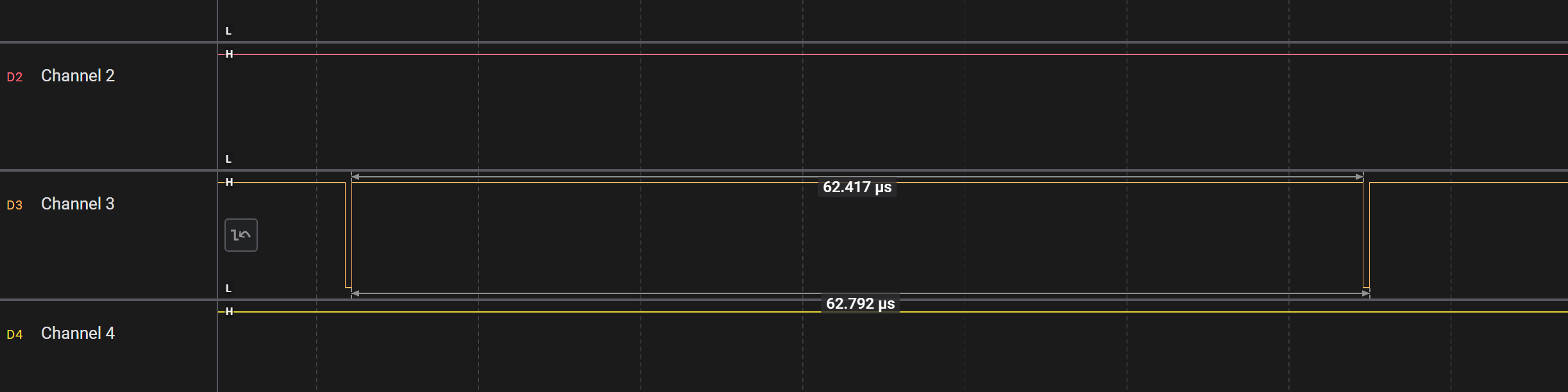
实际测量结果非常接近 62.5ns。因此我们接下来可以通过 nop 来制造 62.5ns 延迟,4 个 nop 指令可以延时 250ns。
下一个目标是寻找到一个方法,快速把 GPIO 置为高电平和低电平。STM8 可以直接修改 GPIO 的 ODR 寄存器:
#define setBit(reg, bit) (reg = reg | (1 << bit))
#define clearBit(reg, bit) (reg = reg & ~(1 << bit))
#define toggleBit(reg, bit) (reg = reg ^ (1 << bit))
#define setHigh setBit(GPIOA->ODR, 2)
#define setLow clearBit(GPIOA->ODR, 2) 实际测试一下。连续交替调用 setHigh 和 setLow:
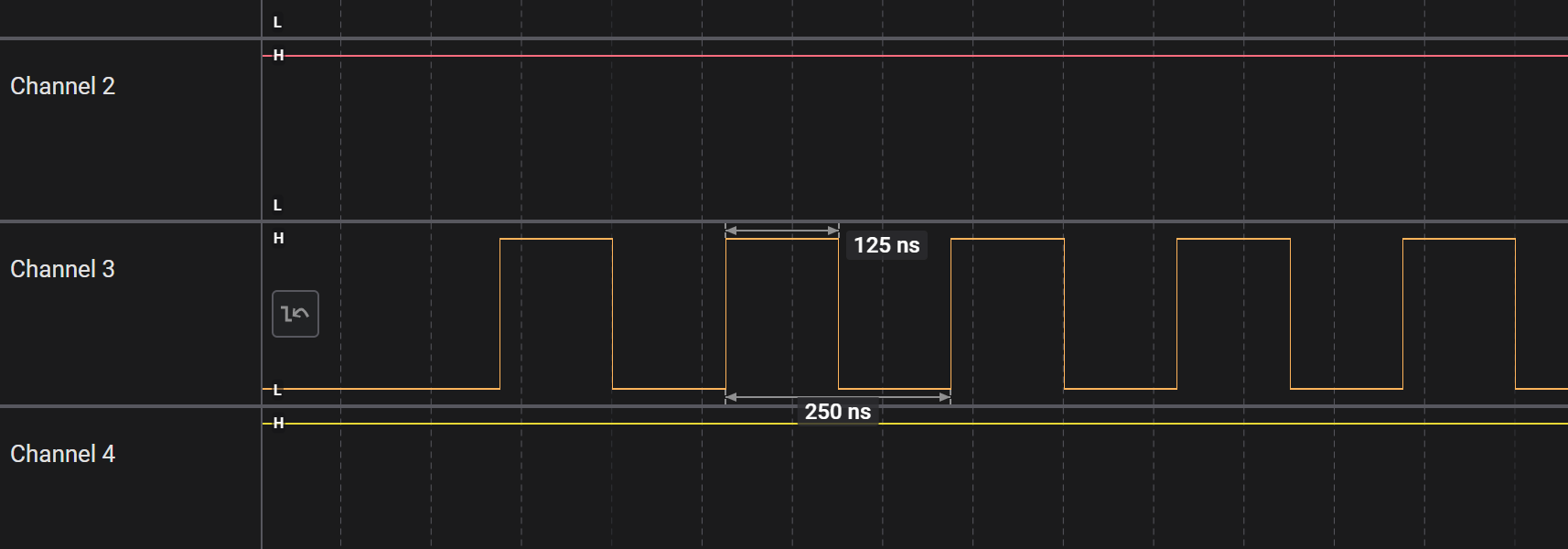
可见 setHigh/setLow 的时间消耗是 125ns,即两个时钟周期。我们查看汇编码:
_loop:
; src\main.c: 98: while(1) {
00102$:
; src\main.c: 99: setHigh;
bset 20480, #2
; src\main.c: 100: setLow;
bres 20480, #2
; src\main.c: 101: setHigh;
bset 20480, #2
; src\main.c: 102: setLow;
bres 20480, #2
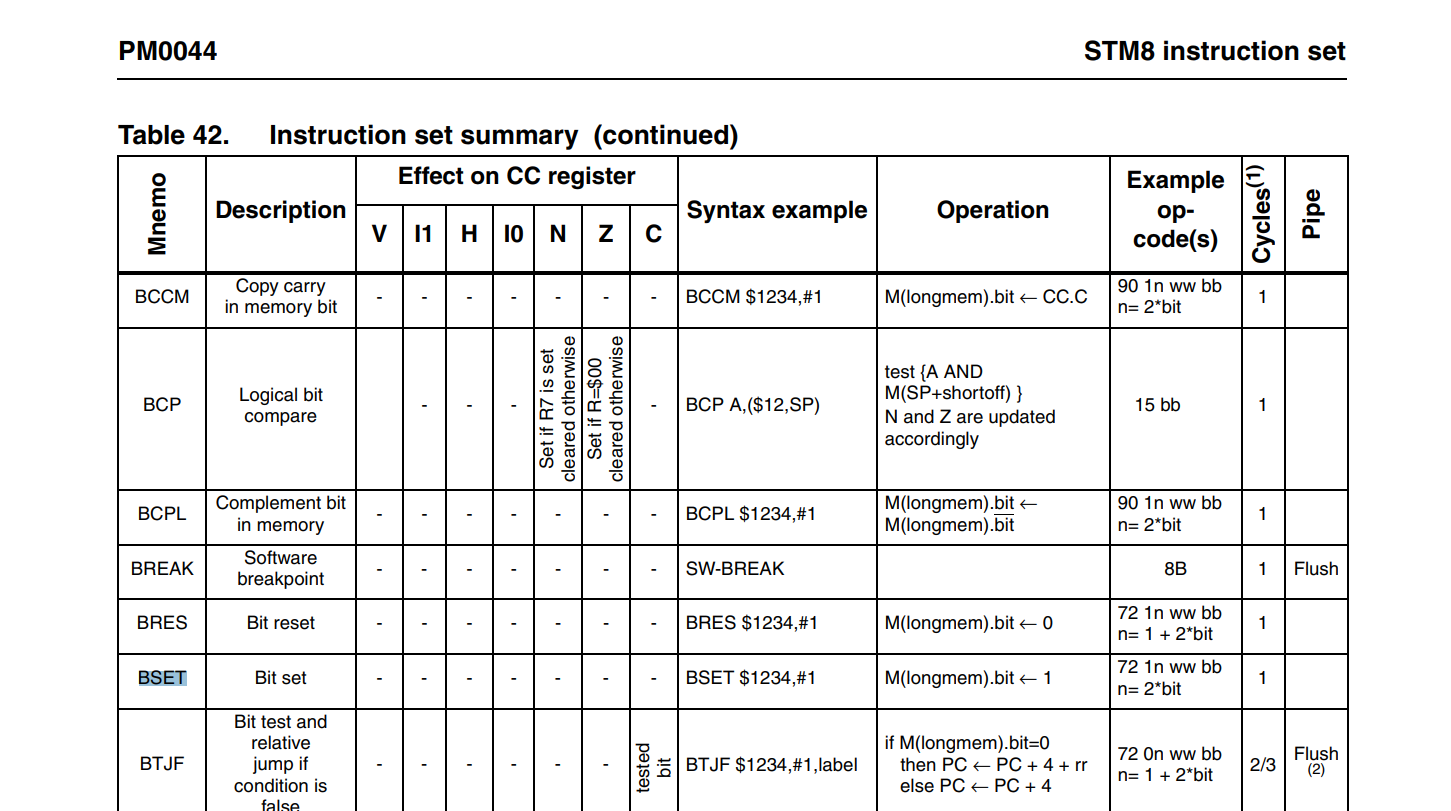
; ... 可见实际使用了单条汇编指令 bset/bres 来设置寄存器的特定位置。然而,查阅 STM8 手册,发现手册将其描述为单周期指令:
显然这不正常。查到 stackoverflow 上的一条回答:
It is explained in section 5.4, which basically says that throughout the programming manual, "a simplified convention providing a good match with reality" will be used. From my experience, this simplified convention is indeed a good approximate for a longer sequence, but unusable for exact per-instruction timing, even if you're working on assembly level and control alignment. Take "SLA addr" as an example. It is documented to use 1 cycle. Put three of them in sequence to implement the C equivalent of "*(addr) << 3", and you'll clock up 5-6 cycles.
Actual cycles used for decoding and execution are undocumented. Apart from the obvious reasons, there is no comprehensive documentation about what causes pipeline stalls. I was able to get some insight into this by configuring TIM2 with a prescaler of /1 and reload values of 0xFFFF while using ST-LINK/V2 to step through my code. You can then keep a watch on TIM2_CNTRL to see cycles consumed (== the aggregate value of executing the previous and decoding the current instruction).
简而言之,STM8 有三级流水线(取值、译码、执行),文档中没详细说明译码和执行的周期。看来我们需要靠实验(而非理论计算)来寻找合适的汇编序列,以满足本任务的时序要求了。
最终结果如下:
// 期望:high 400ns, low 850ns
// 实际:high 375~417ns, low 833~875ns
#define send_0 { \
__asm__("bset 20480, #2"); \
__asm__( \
"nop\nnop\nnop\nnop\nnop\n" \
); \
__asm__("bres 20480, #2"); \
__asm__( \
"nop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\n" \
); \
}
// 期望:high 800ns, low 450ns
// 实际:high 792~833ns, low 417~458ns
#define send_1 { \
__asm__("bset 20480, #2"); \
__asm__( \
"nop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\nnop\n" \
); \
__asm__("bres 20480, #2"); \
__asm__( \
"nop\nnop\nnop\n" \
); \
}现在来控制单个 LED。根据文档,这 24bit 的发送顺序是 GRB:

我们把这些 bit 打包进一个 uint32 的低 24 位输出:
void send_raw_color(uint32_t color) {
for(int i=0; i<24; i++) {
if(color & 1) {
send_1;
} else {
send_0;
}
color >>= 1;
}
}
void loop() {
while(1) {
send_raw_color(0);
delay(100);
send_raw_color(0b100000000000000010000000);
delay(100);
}
}代码成功工作,让 LED 闪烁显示 G=1, R=0, B=1 的颜色。但是我们看一眼逻辑分析仪,时序实际上是不符合要求的:

这是因为我们有判断、自增和右移语句,拖慢了速度,低电平时长接近 2us;但 LED 仍然正常运行。我们做一些极限测试:
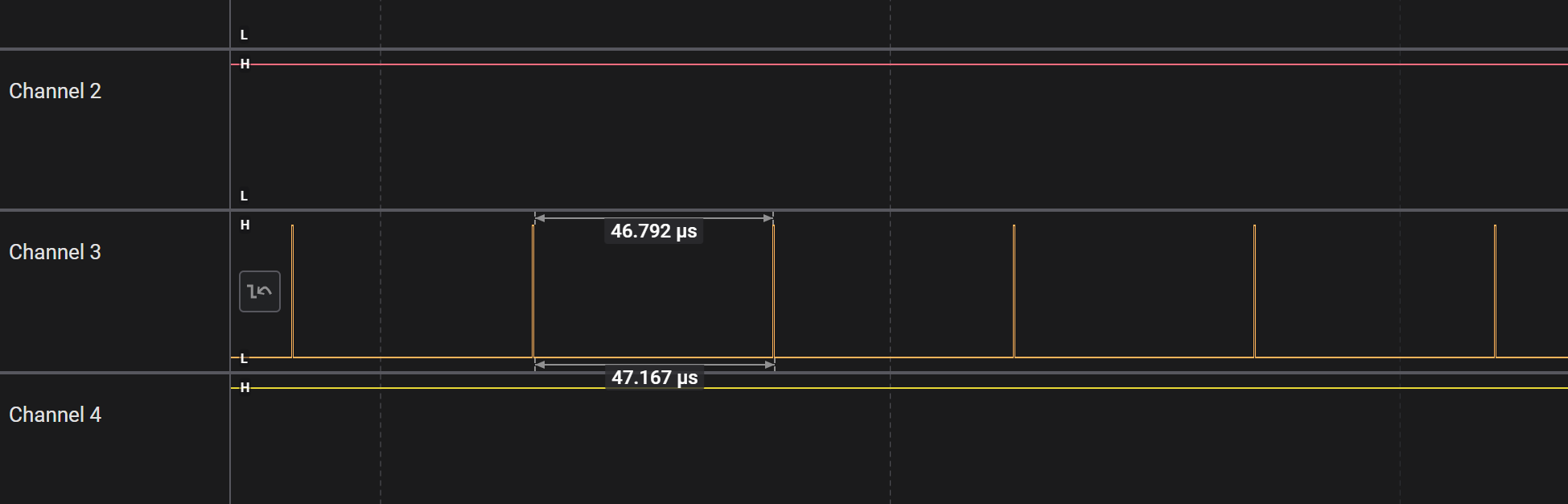
在低电平时长接近 50us 的情况下,LED 仍然能被正确地驱动。当低电平时长略微超过 50us 时,开始闪烁其它各种颜色。这说明 WS2812B 应该是主要关注高电平的时间长短,低电平时长只要不超过 50us(报文间的最小间隔时长)就没问题。算是鲁棒性很强了。
0x05 渐变霓虹灯
来做一个简单的颜色渐变的霓虹灯(刷新率≈100Hz)。
void send_rgb(uint8_t r, uint8_t g, uint8_t b) {
uint32_t raw = 0;
uint32_t rev_r = 0, rev_g = 0, rev_b = 0;
for(int i=0; i<8; i++)
rev_r |= (((r>>(7-i)) & 1) ? (1<<i) : 0);
for(int i=0; i<8; i++)
rev_g |= (((g>>(7-i)) & 1) ? (1<<i) : 0);
for(int i=0; i<8; i++)
rev_b |= (((b>>(7-i)) & 1) ? (1<<i) : 0);
raw = (rev_b << 16) | (rev_r << 8) | rev_g;
send_raw_color(raw);
}
int r, g, b;
int fr = 1, fg = 1, fb = 1;
void update_color() {
if(r == 255) fr = -1;
if(r == 0) fr = 1;
r += fr;
if(g == 255) fg = -1;
if(g == 0) fg = 1;
g += fg;
if(b == 255) fb = -1;
if(b == 0) fb = 1;
b += fb;
}
void setup() {
pinMode(LED_PIN, OUTPUT);
r = rand() % 256;
g = rand() % 256;
b = rand() % 256;
}
void loop() {
while(1) {
update_color();
send_rgb(r, g, b);
delay(10);
}
}效果: