

0x00 bit banging
在 MCS-51 的时代,人们经常用 cpu 操作 GPIO,以对一些协议进行软件实现。这种手段称为 bit banging。对于 I2C 这样低速且时钟可以由 MCU 自己产生的协议,bit banging 勉强可用;然而,协议速度越快,bit banging 就越困难。另外,bit banging 会占用大量的 cpu 时间。
I2C、SPI、UART 这些外设,在很大程度上解决了上述困境。通讯过程由这些外设自己完成了,而 cpu 在想要发出数据时,就写入外设的 fifo;想要读取数据时,就读取外设的 fifo。cpu 无需关心时序,只需要读写外设寄存器,不仅编程变得更简单,通讯速率还提高了,可谓一举两得。
然而,我们总会遇到外设不够用的时候。例如,RP2040 只提供了两个 UART,但用户可能想要四个;另外,对于一些不常用的协议,没有哪个 MCU 会提供专门的外设,本文要讨论的 WS2812B LED 就是如此。本站在 2022 年写过利用 STM8 驱动 WS2812B 的文章,今天我们试着使用 RP2040 来完成这一任务。
WS2812B 有四个接口:VCC、GND、DIN、DOUT。其中,DOUT 用于串联灯珠,前一个 LED 的 DOUT 连接到后一个 LED 的 DIN。通讯协议非常简单:
- 每颗 LED 的颜色通过 24 个 bit 表示,顺序为 GRB。
- 若有 $n$ 个灯珠,则 MCU 连续发送 $24 n$ 个 bit。一个灯珠在收到报文之后,会将开头的 24 bit 作为自己的配置,然后把剩余的 $24n - 24 $ bit 的数据转发给后面的灯珠。
- 想要发送
0,则把数据线先拉高 400ns,再拉低 850ns;想要发送1,则先拉高 800ns,再拉低 450ns。允许 $\pm$ 150ns 的误差。 - 两条报文之间间隔至少 50us。
在学习 PIO 之前,我们先尝试使用传统的 bit banging 技术。RP2040 的主频(125MHz)远高于笔者 2022 年写文章时采用的 STM8S103(16MHz),因此能实现更精细的时序控制。
RP2040 每个时钟周期是 8ns,所以我们可以用 nop 制造 8ns 的倍数的延时。据此可以写出初步的代码:
#define delay_8ns __asm__("nop");
#define delay_40ns delay_8ns delay_8ns delay_8ns delay_8ns delay_8ns
#define delay_80ns delay_40ns delay_40ns
#define delay_160ns delay_80ns delay_80ns
#define delay_200ns delay_80ns delay_80ns delay_40ns
// 发送 1:拉高 800ns,拉低 450ns
inline void send_1() {
gpio_put(led_pin, true);
delay_200ns;
delay_200ns;
delay_200ns;
delay_200ns;
// 共 nop 800ns
gpio_put(led_pin, false);
delay_200ns;
delay_200ns;
delay_40ns;
delay_8ns;
// 共 nop 448ns
}
int main() {
for(uint i=0; i<100; i++) {
send_1();
}
}我们现在连续发送 1,用逻辑分析仪看看现实情况。结果如下:
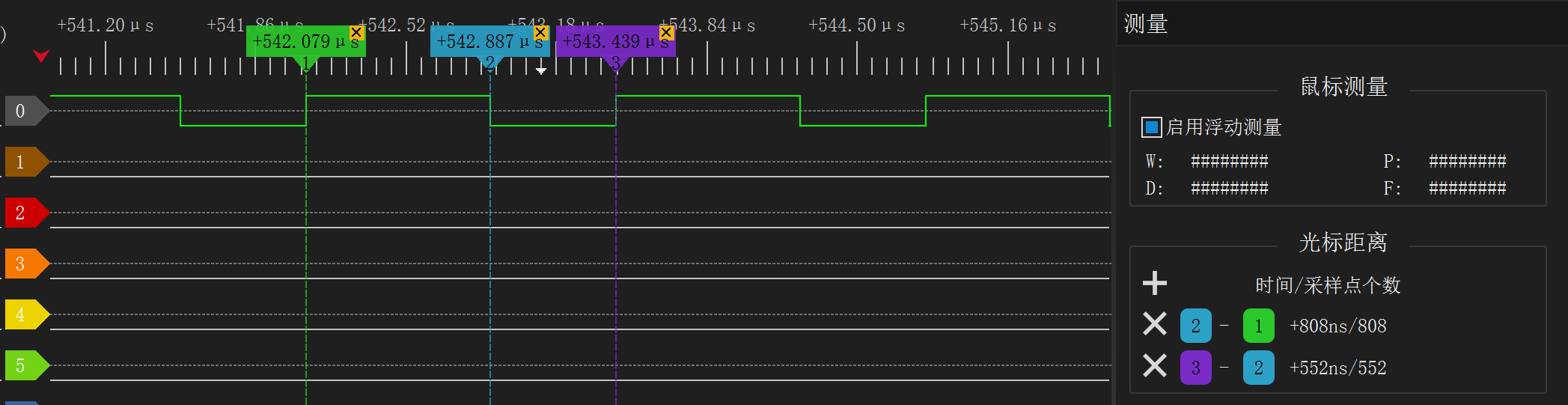
拉高的时间是 808ns,非常好;但拉低的时间是 552ns,误差有点大,这是那个 for 循环的耗时引起的。552ns 即为 69 个时钟周期,而我们 nop 掉的 448ns 为 56 个时钟周期,相差 13 个时钟周期。因此我们少休眠 13 个 nop,就能把低电平时间调到 448ns。调整后的代码:
inline void send_1() {
gpio_put(led_pin, true);
delay_200ns;
delay_200ns;
delay_200ns;
delay_160ns;
delay_8ns; delay_8ns; delay_8ns; delay_8ns;
gpio_put(led_pin, false);
delay_200ns;
delay_80ns;
delay_40ns;
delay_8ns; delay_8ns; delay_8ns;
}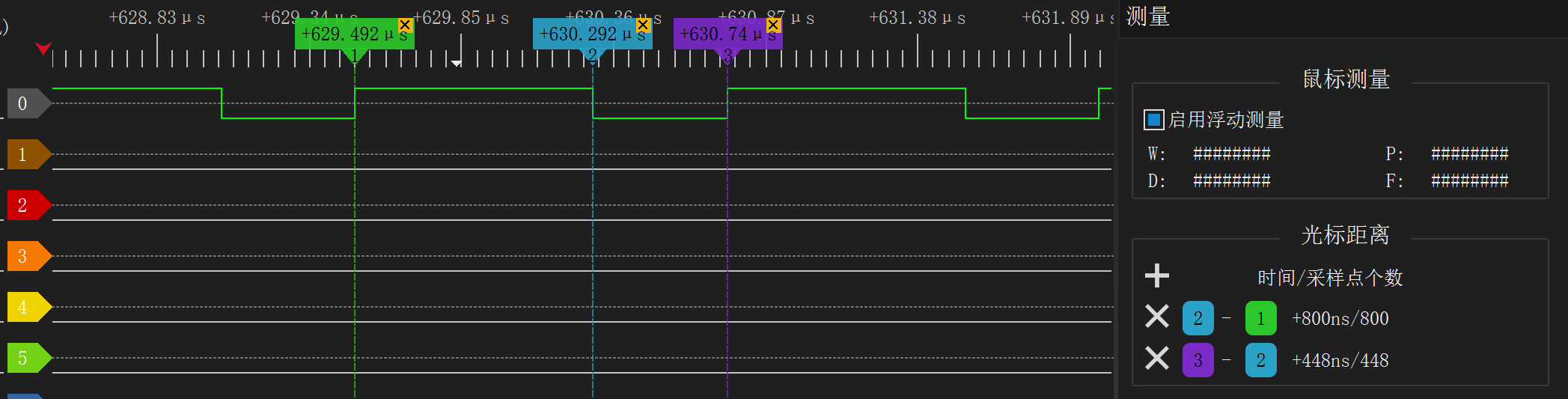
现在我们已经把高电平调到 800ns,低电平 448ns,接近完美。把发送 0 的函数也调好,结果如下:
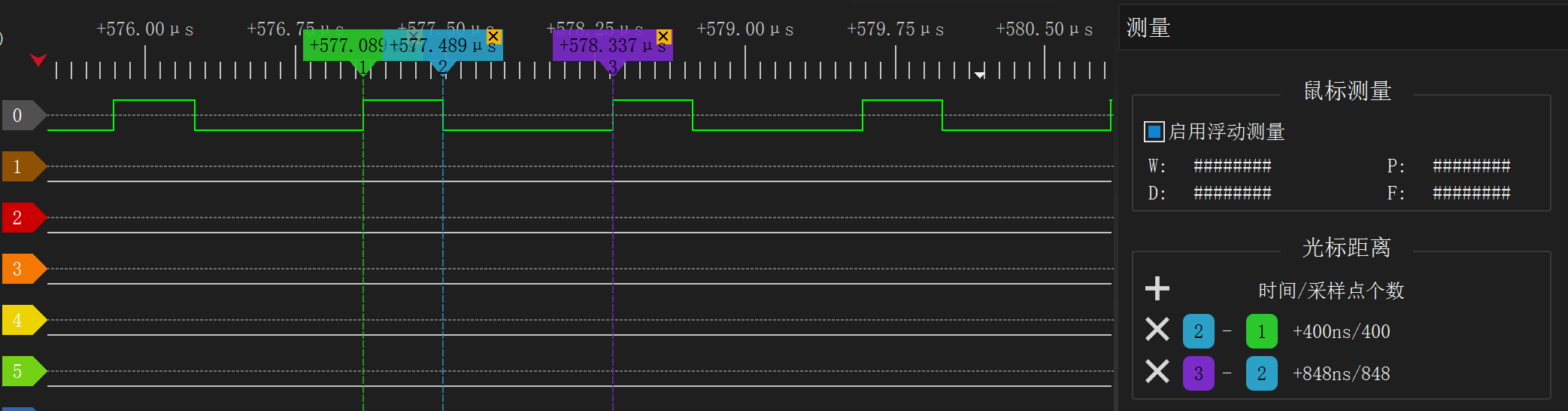
于是可以写出完整代码:
#include "pico/stdlib.h"
#include <stdio.h>
const uint led_pin = 6;
void init() {
gpio_init(led_pin);
gpio_set_dir(led_pin, GPIO_OUT);
gpio_put(led_pin, false);
sleep_ms(10);
}
#define delay_8ns __asm__("nop");
#define delay_40ns delay_8ns delay_8ns delay_8ns delay_8ns delay_8ns
#define delay_80ns delay_40ns delay_40ns
#define delay_160ns delay_80ns delay_80ns
#define delay_200ns delay_80ns delay_80ns delay_40ns
// 发送 0:拉高 400ns,拉低 850ns
void send_0() {
gpio_put(led_pin, true);
delay_200ns;
delay_160ns;
delay_8ns; delay_8ns; delay_8ns; delay_8ns;
gpio_put(led_pin, false);
delay_200ns;
delay_200ns;
delay_200ns;
delay_80ns;
delay_40ns;
delay_8ns; delay_8ns; delay_8ns;
}
// 发送 1:拉高 800ns,拉低 450ns
void send_1() {
gpio_put(led_pin, true);
delay_200ns;
delay_200ns;
delay_200ns;
delay_160ns;
delay_8ns; delay_8ns; delay_8ns; delay_8ns;
gpio_put(led_pin, false);
delay_200ns;
delay_80ns;
delay_40ns;
delay_8ns; delay_8ns; delay_8ns;
}
void send_grb(uint color) {
for(int i=23; i>=0; i--) {
if(color & (1<<i)) {
send_1();
} else {
send_0();
}
}
sleep_us(60);
}
int main() {
stdio_init_all();
puts("Lets go");
init();
for(int i=0; i<10; i++) {
send_grb(0x112233);
}
while(true) {
tight_loop_contents();
}
}然而,这份代码出现了一个怪异的问题。逻辑分析仪显示如下:

在发送第一个报文时,产生了长达 20us 的延迟,而以后的报文均未出现这样的情况,提示这个问题可能与缓存有关。由此,我们马上能联想到 XIP 的实现机制。RP2040 没有内置 ROM,代码存放在外部 flash 上,通过 SPI 协议通讯,但 SPI 协议速率不足以支撑如此快的指令读取速度。因此,RP2040 内置了一块 16 KB 的 SRAM,专门用于给 flash 提供 cache,从而实现近乎 execute-in-place 的效果。而若缓存未命中,则需从 flash 芯片取出代码,这会造成延时。
pico sdk 提供了几个选项,让我们指定代码执行方式。其中一种是 copy_to_ram,即在程序运行之初,将 ROM 拷贝到 RAM。

我们在 CMakeLists.txt 里加上这句话:
pico_set_binary_type(bitbanging copy_to_ram)再观察 GPIO 输出信号,果然解决了问题:

回头观察 copy_to_ram 是如何实现的。默认条件下,RP2040 启动时,只会把 writebale 变量和带有 __not_in_flash_func 标记的函数搬运到 RAM 上;而开启 copy_to_ram 选项时,整个代码都会被复制。用 IDA 看一眼启动流程:

要拷贝哪些内容,是 data_cpy_table 决定的。这张表位于 pico sdk 的 src/rp2_common/pico_standard_link/crt0.S 位置,代码如下:
.align 2
data_cpy_table:
#if PICO_COPY_TO_RAM
.word __ram_text_source__
.word __ram_text_start__
.word __ram_text_end__
#endif
.word __etext
.word __data_start__
.word __data_end__
.word __scratch_x_source__
.word __scratch_x_start__
.word __scratch_x_end__
.word __scratch_y_source__
.word __scratch_y_start__
.word __scratch_y_end__
.word 0 // null terminator因此,我们使用 copy_to_ram 时,会定义编译 flag -DPICO_COPY_TO_RAM,于是 text 段也被包含进 data_cpy_table,在程序复位时复制到 RAM 中。
以上,我们通过 bit banging 成功驱动了这颗 LED。我们在实践中发现几个缺陷:
- cpu 在通讯期间不能从事其他活动。
- 时序要求苛刻,需要在代码中堆积
nop等汇编码。 - 中断和 XIP 缓存不命中等事件都可能破坏时序。
而 RP2040 独特的 PIO(programmable input/output)功能,便是为解决这些问题而生的。
0x01 初探 PIO
RP2040 datasheet 和 pico sdk 文档各自用了一整个章节来描述 PIO 功能。RP2040 片上共有两个 PIO block,每个 PIO block 都直连 bus fabric 和 GPIO,结构如下图:
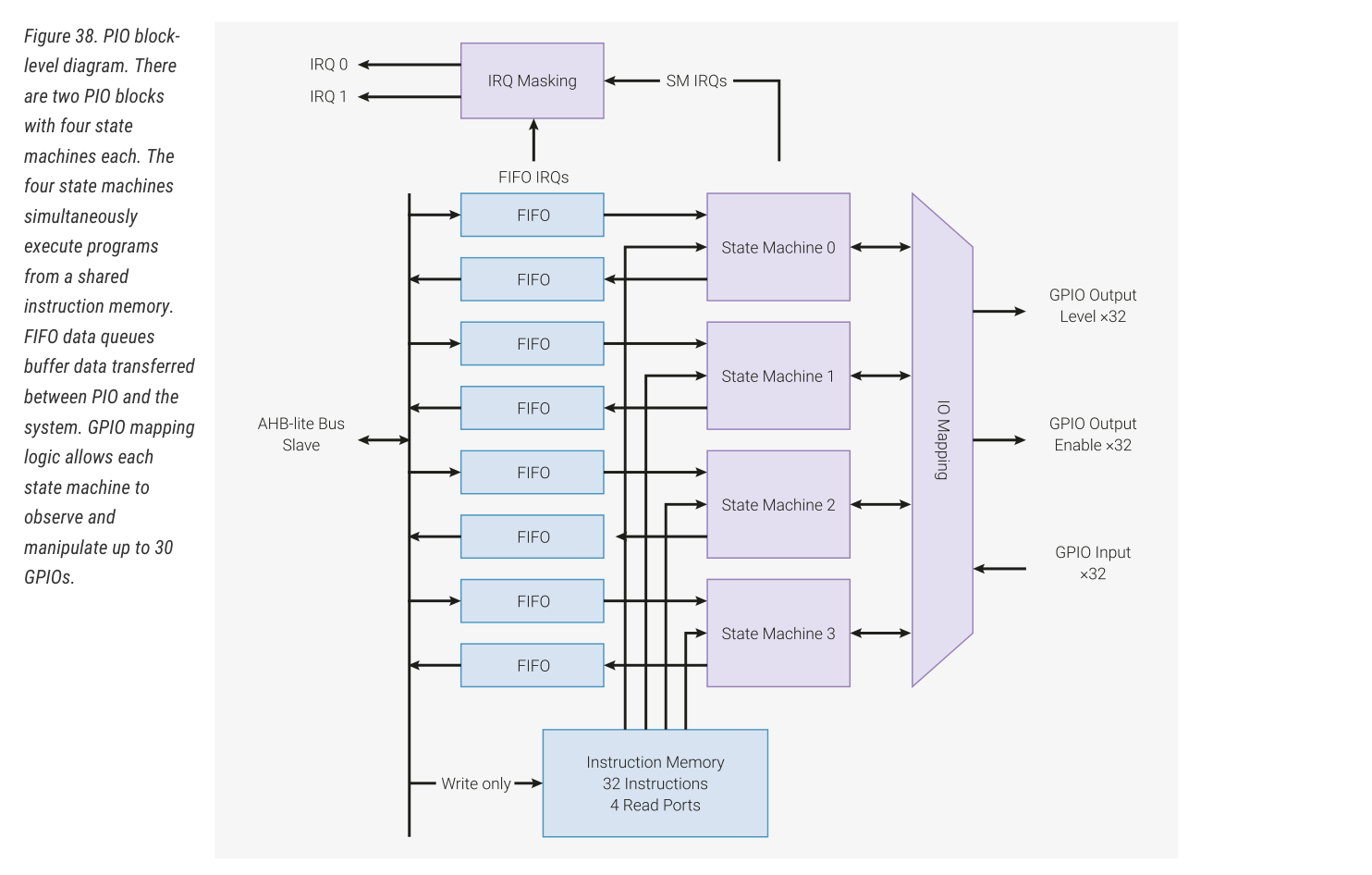
每个 PIO block 拥有 4 个状态机,每个状态机拥有:
- 两个 32-bit 移位寄存器(ISR、OSR);
- 两个 32-bit 临时寄存器(X、Y);
- TX 和 RX 方向的 4 × 32-bit fifo,也可以配置为单方向的 8 × 32-bit fifo;
- 分数时钟分频器;
- 灵活的 GPIO 映射(所有状态机都可以独立、同时访问任何 GPIO);
- DMA 接口;
- IRQ。
状态机的结构如下图:
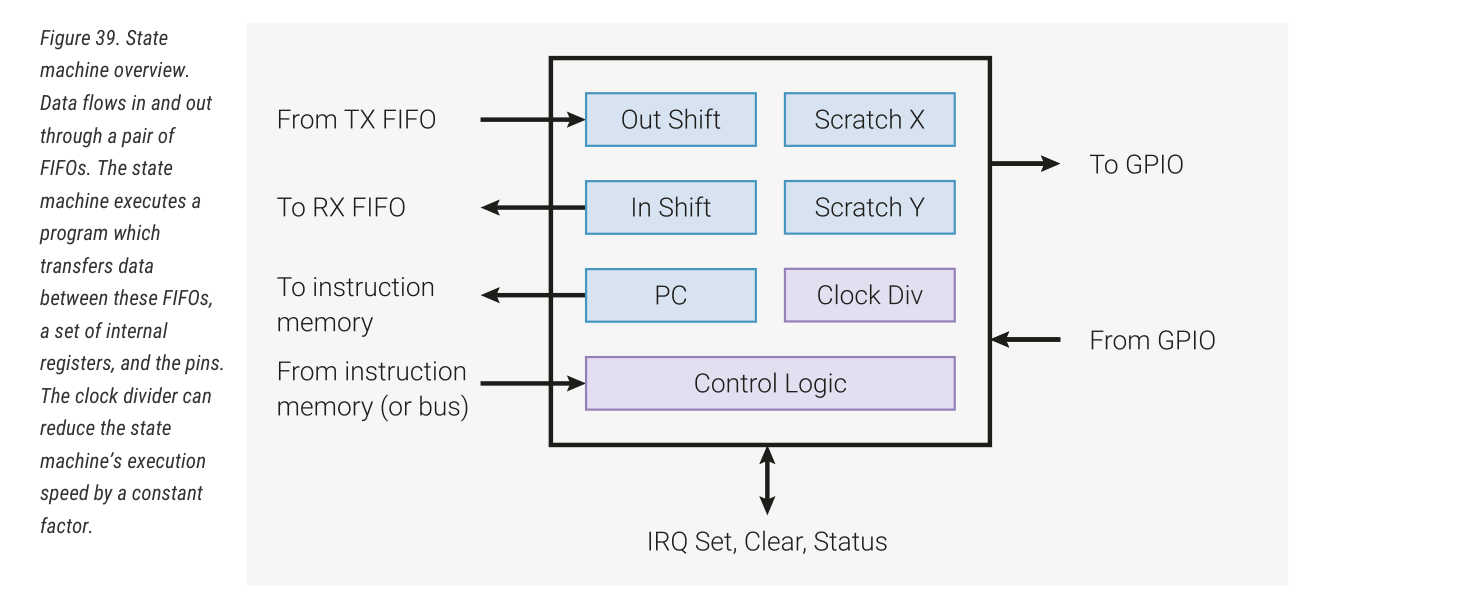
一般而言,我们给状态机编程之后,它就会执行某种数据传输程序。MCU 想要借助 PIO 发送内容时,就写入 tx fifo;想要接收内容,就读取 rx fifo。PIO 的指令集仅有 9 条(JMP, WAIT, IN, OUT, PUSH, PULL, MOV, IRQ, SET),文档中给了一个 PIO 程序的例子:
.program squarewave
set pindirs, 1 ; Set pin to output
again:
set pins, 1 [1] ; Drive pin high and then delay for one cycle
set pins, 0 ; Drive pin low
jmp again ; Set PC to label `again`在每个时钟周期内,状态机执行一条指令。每条指令耗时一个时钟周期(除非显式地暂停)。另外,可以设置指令执行完成之后的延时(最多 31 个周期)。
每个 PIO block 拥有 32 条指令的空间,状态机的 PC 寄存器会指向自己正在运行的指令。我们可以同时运行多个状态机,由于指令执行时间是确定性的,它们能完全同步。
指令的具体定义可参考 datasheet。简而言之:
PULL:从 tx fifo 取 32 bit 放进 OSR 寄存器。OUT:对 OSR 寄存器进行移位,移出的若干 bit 输出到其他位置。IN:对 ISR 寄存器进行移位,读取若干 bit。PUSH:将 ISR 的内容写进 rx fifo,同时清空 ISR 寄存器。WAIT:等待某种条件,例如等 GPIO 变高、等中断。JMP:跳转到特定的绝对位置。可以带条件。MOV:复制值。可以对数据进行变换,例如取反。IRQ:设置或清除中断标志。SET:把立即数写进目标位置。可以用于设置 GPIO。
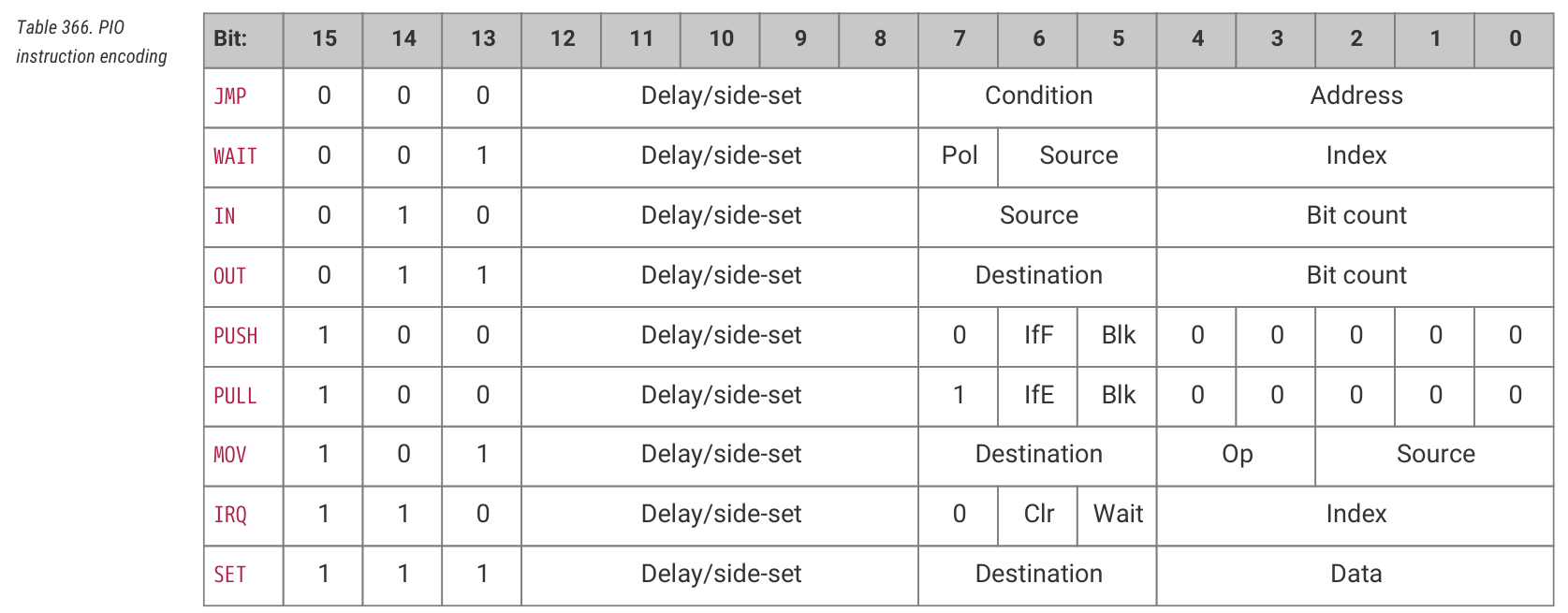
有一些特性值得一提:
- side-set,它可以在指令执行的同时,去设置 GPIO。注意它与 delay 共用 5bit 的空间,有时需要取舍。
- program wrapping,当 PC 经过
EXECCTRL_WRAP_TOP位置之后,自动跳到EXECCTRL_WRAP_BOTTOM位置。这可以用来节省一个jmp指令。 - fifo joining,可以把 fifo 从 4 rx、4 tx 改成深度为 8 的单向的 fifo。
- autopush/autopull,在 OSR 和 ISR 的数据被移出之后,自动从 fifo 移入数据。
- 分频,便于与低速设备通讯。
- GPIO 映射。每个状态机有以下三个寄存器:
PINCTRL_OUT_BASE, PINCTRL_SET_BASE, PINCTRL_SIDESET_BASE。这使得 OUT、SET、side-set 指令可以操作不同的 GPIO 区域,其中 OUT 可以写 32 个 GPIO,SET 和 side-set 至多写 5 个。
0x02 用 PIO 实现 blink
pico-examples 给出了很多 PIO 使用例,我们先来观察 blink 的实现。CMakeLists.txt 内容如下:
add_executable(pio_blink blink.c)
pico_generate_pio_header(pio_blink ${CMAKE_CURRENT_LIST_DIR}/blink.pio)
target_link_libraries(pio_blink pico_stdlib hardware_pio)
pico_add_extra_outputs(pio_blink)
其中使用 pico_generate_pio_header 指令,把 .pio 文件编译成了 .h 文件。 blink.pio 内容为:
;
; Copyright (c) 2020 Raspberry Pi (Trading) Ltd.
;
; SPDX-License-Identifier: BSD-3-Clause
;
; SET pin 0 should be mapped to your LED GPIO
.program blink
pull block
out y, 32
.wrap_target
mov x, y
set pins, 1 ; Turn LED on
lp1:
jmp x-- lp1 ; Delay for (x + 1) cycles, x is a 32 bit number
mov x, y
set pins, 0 ; Turn LED off
lp2:
jmp x-- lp2 ; Delay for the same number of cycles again
.wrap ; Blink forever!
% c-sdk {
// this is a raw helper function for use by the user which sets up the GPIO output, and configures the SM to output on a particular pin
void blink_program_init(PIO pio, uint sm, uint offset, uint pin) {
pio_gpio_init(pio, pin);
pio_sm_set_consecutive_pindirs(pio, sm, pin, 1, true);
pio_sm_config c = blink_program_get_default_config(offset);
sm_config_set_set_pins(&c, pin, 1);
pio_sm_init(pio, sm, offset, &c);
}
%}
这份文件分为 PIO 指令和 C 语言两个部分。先分析 PIO 指令:
.program blink
pull block ; 从 TX fifo 取 32bit,送进 OSR
out y, 32 ; 把 OSR 寄存器输出到 Y 寄存器
.wrap_target
mov x, y ; X = Y
set pins, 1 ; 打开 LED
lp1:
jmp x-- lp1 ; 延迟 y + 1 个时钟周期
mov x, y ; X = Y
set pins, 0 ; 关闭 LED
lp2:
jmp x-- lp2 ; 延迟 y + 1 个时钟周期
.wrap
这份代码使用了 program wrapping 特性,让程序执行主循环而不耗费额外的 jmp。第一句 pull block 是阻塞的,所以等到 cpu 往 fifo 中发送数据之后,才开始执行后续逻辑。X 是递减器,用于延时。
x-- 但不支持 --x。 再看 C 语言部分。
// this is a raw helper function for use by the user which sets up
// the GPIO output, and configures the SM to output on a particular pin
void blink_program_init(PIO pio, uint sm, uint offset, uint pin) {
// 把特定 GPIO 的功能设为 PIO
pio_gpio_init(pio, pin);
// 设置 GPIO 方向(由状态机调用 SET 指令实现)
pio_sm_set_consecutive_pindirs(pio, sm, pin, 1, true);
// 设置 SET_BASE 为 pin,SET_COUNT 为 1
pio_sm_config c = blink_program_get_default_config(offset);
sm_config_set_set_pins(&c, pin, 1);
// 初始化状态机
pio_sm_init(pio, sm, offset, &c);
}这里引用了一个我们没见过的函数 blink_program_get_default_config,它应该是自动生成的。我们观察 pioasm 生成的 blink.pio.h:
// -------------------------------------------------- //
// This file is autogenerated by pioasm; do not edit! //
// -------------------------------------------------- //
#pragma once
#if !PICO_NO_HARDWARE
#include "hardware/pio.h"
#endif
// ----- //
// blink //
// ----- //
#define blink_wrap_target 2
#define blink_wrap 7
static const uint16_t blink_program_instructions[] = {
0x80a0, // 0: pull block
0x6040, // 1: out y, 32
// .wrap_target
0xa022, // 2: mov x, y
0xe001, // 3: set pins, 1
0x0044, // 4: jmp x--, 4
0xa022, // 5: mov x, y
0xe000, // 6: set pins, 0
0x0047, // 7: jmp x--, 7
// .wrap
};
#if !PICO_NO_HARDWARE
static const struct pio_program blink_program = {
.instructions = blink_program_instructions,
.length = 8,
.origin = -1,
};
static inline pio_sm_config blink_program_get_default_config(uint offset) {
pio_sm_config c = pio_get_default_sm_config();
sm_config_set_wrap(&c, offset + blink_wrap_target, offset + blink_wrap);
return c;
}
// this is a raw helper function for use by the user which sets up the GPIO output, and configures the SM to output on a particular pin
void blink_program_init(PIO pio, uint sm, uint offset, uint pin) {
pio_gpio_init(pio, pin);
pio_sm_set_consecutive_pindirs(pio, sm, pin, 1, true);
pio_sm_config c = blink_program_get_default_config(offset);
sm_config_set_set_pins(&c, pin, 1);
pio_sm_init(pio, sm, offset, &c);
}
#endif
可见,这份 blink.pio.h 就是把 blink.pio 中的指令汇编码翻译成字节码,提供一个 blink_program和一个 blink_program_get_default_config 函数,然后照抄 blink.pio 中的 c-sdk 部分。
最后来看主程序。
/**
* Copyright (c) 2020 Raspberry Pi (Trading) Ltd.
*
* SPDX-License-Identifier: BSD-3-Clause
*/
#include <stdio.h>
#include "pico/stdlib.h"
#include "hardware/pio.h"
#include "hardware/clocks.h"
#include "blink.pio.h"
void blink_pin_forever(PIO pio, uint sm, uint offset, uint pin, uint freq);
int main() {
setup_default_uart();
// todo get free sm
PIO pio = pio0;
uint offset = pio_add_program(pio, &blink_program);
printf("Loaded program at %d\n", offset);
blink_pin_forever(pio, 0, offset, 0, 3);
blink_pin_forever(pio, 1, offset, 6, 4);
blink_pin_forever(pio, 2, offset, 11, 1);
}
void blink_pin_forever(PIO pio, uint sm, uint offset, uint pin, uint freq) {
blink_program_init(pio, sm, offset, pin);
pio_sm_set_enabled(pio, sm, true);
printf("Blinking pin %d at %d Hz\n", pin, freq);
// PIO counter program takes 3 more cycles in total than we pass as
// input (wait for n + 1; mov; jmp)
pio->txf[sm] = (clock_get_hz(clk_sys) / (2 * freq)) - 3;
}
首先通过 pio_add_program 加载 PIO 程序,然后调用 sdk-c 中的 blink_program_init() 初始化状态机,并调用 pio_sm_set_enabled() 启动状态机。写入 pio->txf[sm] 即为向 tx fifo 发送信息。
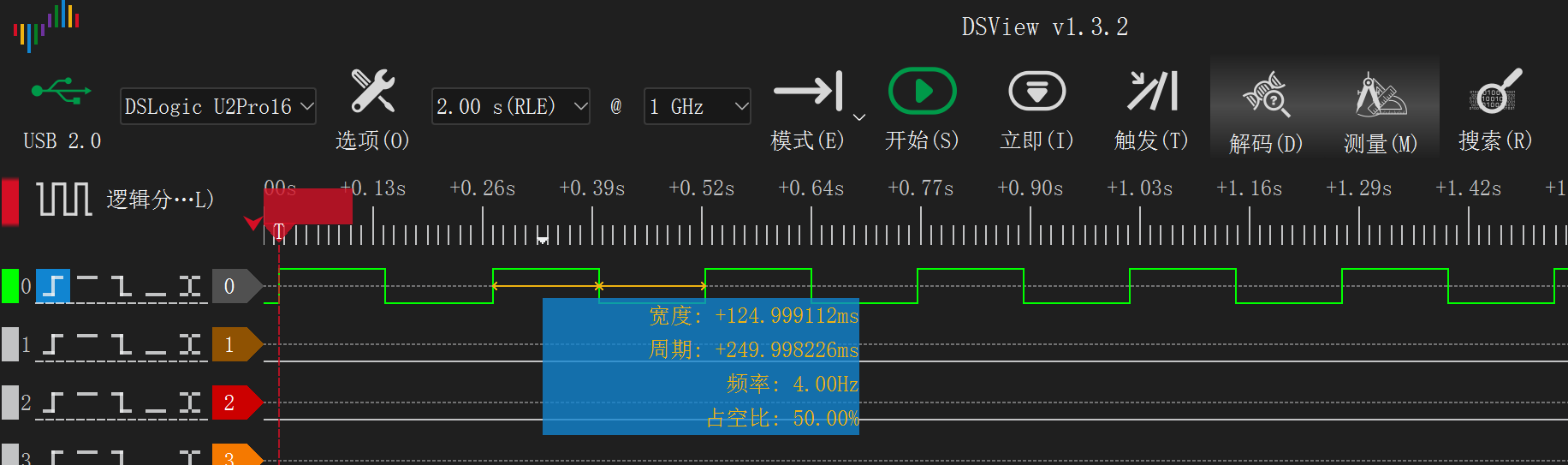
0x03 用 PIO 快速翻转 GPIO
看完了例子,我们来自己写一个 PIO 程序。任务是:在每个时钟周期内,翻转 GPIO6 和 GPIO7,且这两个 GPIO 的电平相反。
我们有四种设置 GPIO 的方式,分别是 OUT 指令、SET 指令、MOV 指令和 side-set。我们考虑 SET 和 side-set。假如用 SET,那么可以一次性设置两个 GPIO,写法如下:
.program flip
.wrap_target
set pins, 0b01
set pins, 0b10
.wrap
要让它工作,我们得设置 PINCTRL 寄存器的 SET_BASE 为 6、 SET_COUNT 为 2。这可以通过 sm_config_set_set_pins() API 完成,无需手动操作寄存器。
我们这次不使用 c-sdk 块,而是把状态机初始化的代码全部写进 main.cpp。代码如下:
#include "pico/stdlib.h"
#include <cstdio>
#include "flip.pio.h"
int main() {
stdio_init_all();
uint offset = pio_add_program(pio0, &flip_program);
printf("load offset: %d\n", offset);
// 将两个 GPIO 的 function 设为 PIO0
pio_gpio_init(pio0, 6);
pio_gpio_init(pio0, 7);
// 设置 GPIO 方向为输出
pio_sm_set_consecutive_pindirs(pio0, 0, 6, 2, true);
// 设置状态机
auto c = flip_program_get_default_config(offset);
sm_config_set_set_pins(&c, 6, 2);
pio_sm_init(pio0, 0, offset, &c);
// 启动状态机
pio_sm_set_enabled(pio0, 0, true);
while(true) {
tight_loop_contents();
}
}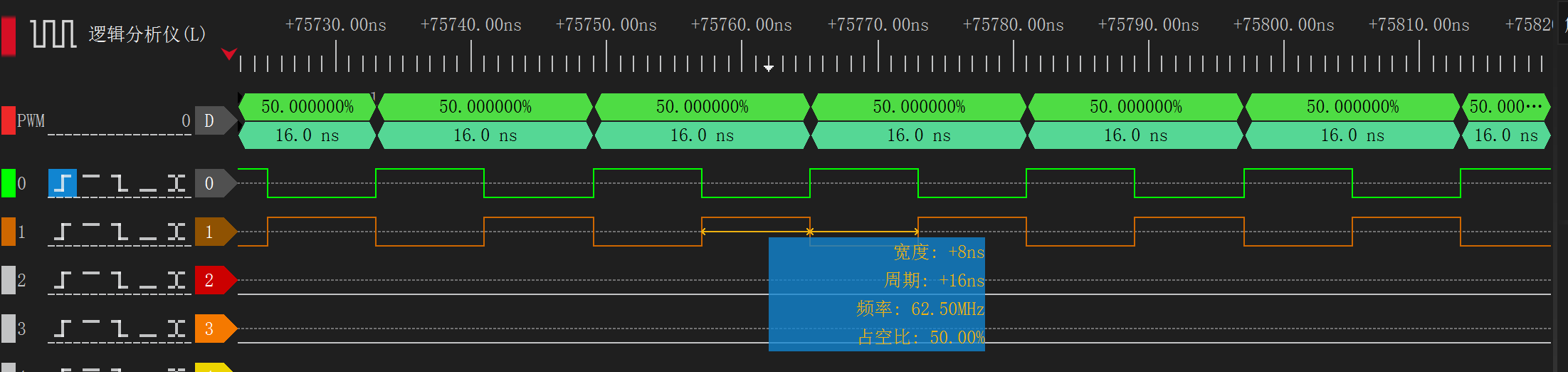
可见功能运行正常。
当然,我们也可以使用 side-set 来实现。下面的代码并不使用 wrap 特性,而是在 jmp 指令的同时设置 GPIO:
.program flip
.side_set 2
loop:
nop side 0b01
jmp loop side 0b10其中,.side_set 2 表示 side-set 要占用 2bit 的指令空间(也就是说,只剩下 3bit 留给 delay)。在翻译出的 flip.pio.h 文件中体现为:
static inline pio_sm_config flip_program_get_default_config(uint offset) {
pio_sm_config c = pio_get_default_sm_config();
sm_config_set_wrap(&c, offset + flip_wrap_target, offset + flip_wrap);
sm_config_set_sideset(&c, 2, false, false);
return c;
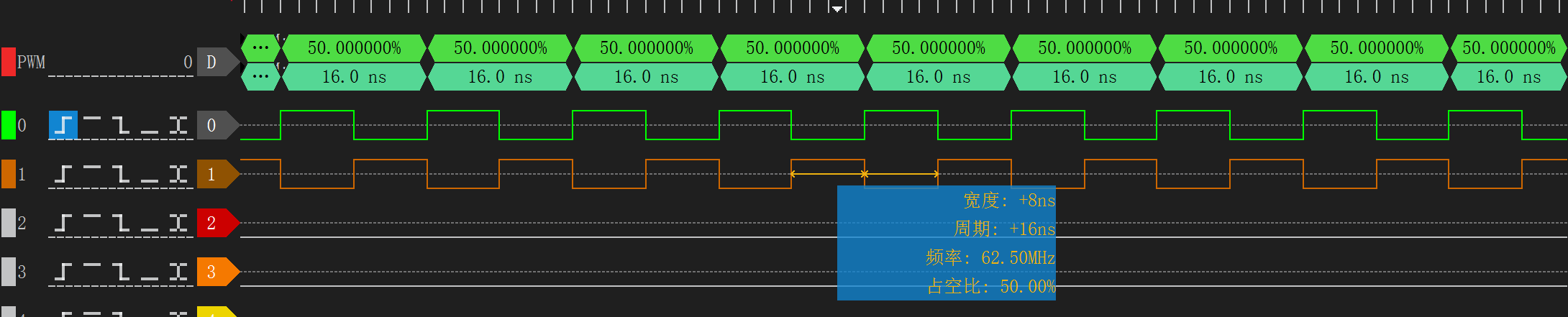
}而 main.cpp 需要执行 sm_config_set_sideset_pins(),以设置 side-set pin base。最终结果:
0x04 用 PIO 控制 WS2812B
现在,我们利用 PIO 来控制 WS2812B,以代替 bit banging。回顾 WS2812B 的控制协议:高 400ns、低 850ns 表示 0;高 800ns、低 450ns 表示 1。当务之急是设计一种方式,去精确制造延时。
PIO 可以分频,且支持分数分频。然而,分频是通过将 $n$ 个系统时钟周期视为一个周期实现(分数分频则是在某些时候等待 $n+1$ 而不是 $n$ 个系统周期),所以,不可能利用分频精确制造出 450ns 这样的延迟。我们只能做到 448ns,不过,WS2812B 允许 150ns 的误差,所以无伤大雅。
我们让 PIO 执行以下流程:
- 使用 pull 拉取 32bit 数据到 OSR,其中 LSB 24bit 是将要输出的 payload。
- OSR 左移 8 bit,抛弃无效数据。
- OSR 左移 24 次,每次一个 bit。对于这个 bit:
- 如果是 0,则拉高 400ns(50 周期)、拉低 848ns(106 周期);
- 否则拉高 800ns(100 周期)、拉低 448ns(56 周期)。
PIO 代码如下:
.program my_ws2812
.wrap_target
pull ; 从 TX 取 32bit 到 OSR
out null, 8 ; 抛掉 MSB 8bit
send_bit:
out x, 1 ; 将 OSR 的 LSB 输出到 x
; 若要发送 0,则拉高 50 周期;要发送 1,则拉高 100 周期
set pins, 1 [20] ; 拉高,然后等待 20 周期
nop [27] ; 等待 28 周期
jmp !x skip_1 ; 若 x=0,则不再等待
nop [20]
nop [28] ; 等待 50 周期
; 若要发送 0,则拉低 106 周期;要发送 1,则拉低 56 周期
skip_1:
set pins, 0 [26] ; 拉低,然后等待 26 周期
nop [25] ; 等待 26 周期
jmp x-- skip_2 ; 若 x=1,则不再等待
nop [20]
nop [28] ; 等待 50 周期
skip_2:
jmp !osre send_bit
.wrapC++ 代码如下:
#include "pico/stdlib.h"
#include <cstdio>
#include "my_ws2812.pio.h"
int main() {
stdio_init_all();
uint offset = pio_add_program(pio0, &my_ws2812_program);
printf("load offset: %d\n", offset);
pio_gpio_init(pio0, 6);
pio_sm_set_consecutive_pindirs(pio0, 0, 6, 1, true);
// 设置状态机
auto c = my_ws2812_program_get_default_config(offset);
sm_config_set_set_pins(&c, 6, 1);
sm_config_set_out_shift(&c, false, false, 32);
pio_sm_init(pio0, 0, offset, &c);
// 启动状态机
pio_sm_set_enabled(pio0, 0, true);
pio0->txf[0] = 0x010101;
pio0->txf[0] = 0x020202;
pio0->txf[0] = 0x030303;
pio0->txf[0] = 0x040404;
while(true) {
tight_loop_contents();
}
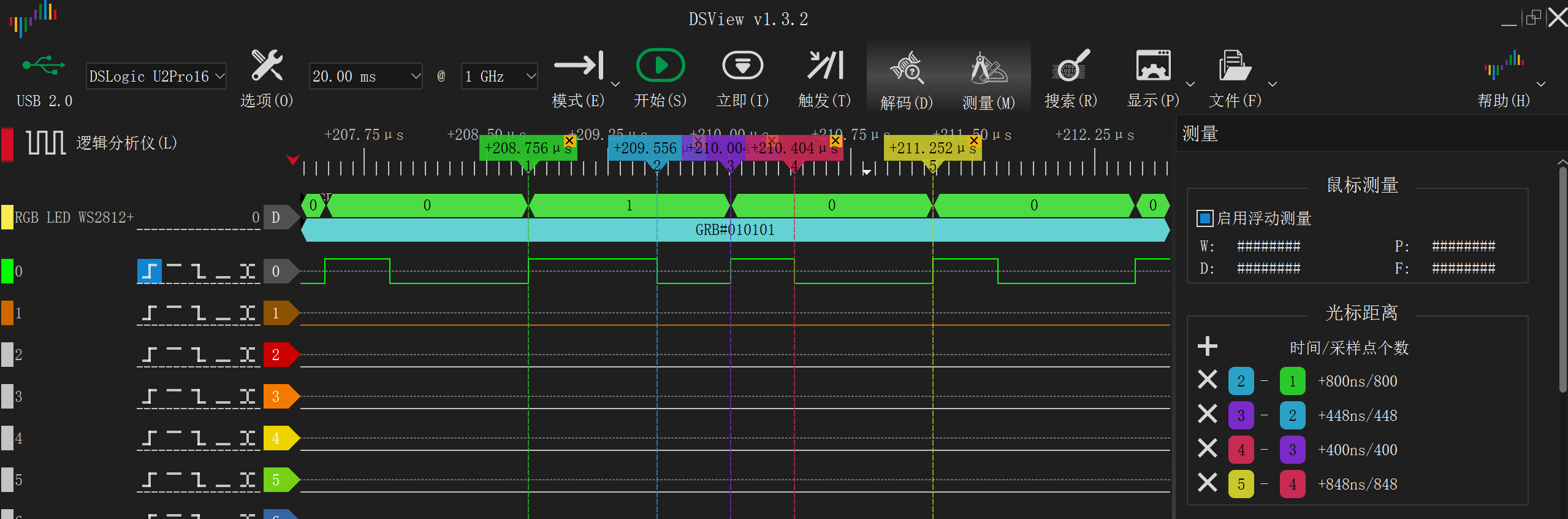
}结果如下,时序几乎完美(每 24bit 之间可能会浪费几个时钟周期):

0x05 DMA + PIO
现在,我们想要给 LED 发送数据,只需把 GRB 值写入 pio0->txf[0]。然而,队列是会满的,如果我们让 cpu 轮询队列情况,等到队列空了再写入下一个 GRB 值,则与 bit banging 一样浪费 cpu 时间。这个问题可以由 DMA 解决。
PIO 和 DMA 都接入了 bus fabric,所以 DMA 可以直接向 PIO 的寄存器搬运数据。另外,PIO 可以产生 DREQ 以控制消息发送速率。代码如下:
#include "pico/stdlib.h"
#include <cstdio>
#include "hardware/dma.h"
#include "my_ws2812.pio.h"
void init_pio() {
uint offset = pio_add_program(pio0, &my_ws2812_program);
printf("load offset: %d\n", offset);
pio_gpio_init(pio0, 6);
pio_sm_set_consecutive_pindirs(pio0, 0, 6, 1, true);
// 设置状态机
auto c = my_ws2812_program_get_default_config(offset);
sm_config_set_set_pins(&c, 6, 1);
sm_config_set_out_shift(&c, false, false, 32);
pio_sm_init(pio0, 0, offset, &c);
// 启动状态机
pio_sm_set_enabled(pio0, 0, true);
}
int main() {
stdio_init_all();
init_pio();
static uint32_t data[256];
for(uint i=0; i<256; i++) {
data[i] = 0x010101 * i;
}
int chan = dma_claim_unused_channel(true);
dma_channel_config c = dma_channel_get_default_config(chan);
channel_config_set_dreq(&c, DREQ_PIO0_TX0);
dma_channel_configure(
chan,
&c,
&pio0->txf[0],
data,
count_of(data),
true
);
while(true) {
tight_loop_contents();
}
}测试结果:

物理层通讯是 PIO 负责的,数据搬运是 DMA 负责的。现在我们彻底解放了 cpu。