
0x00 动机
如读者所见,本站近期正在连载《Suricata 源码阅读》系列文章。不同于笔者早些时候研究过的 AFL、cyw43、debugprobe 等项目,Suricata 源码规模很大,如果继续使用传统的阅读方式,则有效率低下之虞。举一个例子,在《Suricata 源码阅读(二)》中,笔者见到了以下代码片段:
if (sig->alproto != ALPROTO_UNKNOWN) {
int override_needed = 0;
if (sig->proto.flags & DETECT_PROTO_ANY) {
sig->proto.flags &= ~DETECT_PROTO_ANY;
memset(sig->proto.proto, 0x00, sizeof(sig->proto.proto));
override_needed = 1;
} else {
override_needed = 1;
size_t s = 0;
for (s = 0; s < sizeof(sig->proto.proto); s++) {
if (sig->proto.proto[s] != 0x00) {
override_needed = 0;
break;
}
}
}
if (override_needed)
AppLayerProtoDetectSupportedIpprotos(sig->alproto, sig->proto.proto);
}要分析这段代码,就要知道 proto.proto 有何种用途、如何被设置,然而在初次接触到这份代码的时候,阅读者需要付出很多努力,例如跟进 proto.proto 的 xref,从海量的使用 proto.proto 的代码中找到最原始、最接近其基础语义的那些逻辑。这个过程应该可以交给 LLM 实现。如果 LLM 阅读过整个项目,那它理应能回答我们的各种问题,从而帮助研究者快速理解源码。
CLion 的 xref 功能如此完备,点两下鼠标就能找到所有引用,我们为何要乞灵于 LLM?一方面,xref 只关注于单个符号,然而我们可能对与之相关的很多符号感兴趣——例如,当我们点击 httpStatusOK 的时候,其他相关的符号,例如 httpStatusNotFound 、 httpStatusForbidden 等,可能对我们的分析也有帮助。这是传统 IDE 无法帮到我们的。另一方面,假如我们面前有一个比较复杂的结构,例如一个指针数组,每个指针指向一个双向链表的表头,而表头有指针指向表中的第一个成员和最后一个成员……在 IDE 中多次跳转可能分散研究者的注意力,但 LLM 可以给出比较宏观的分析,让我们跳过那些 trival 的增删改查,把精力投入到核心逻辑上。
为什么不使用 Cursor IDE?Cursor 确实提供了一整套我们所需的功能,可以对 codebase 发起问答,但这一次,笔者希望从零开始研究这项问题,学习 RAG 等技术,以期帮助到未来的 AI 相关项目。
0x01 从 webui 到 langchain
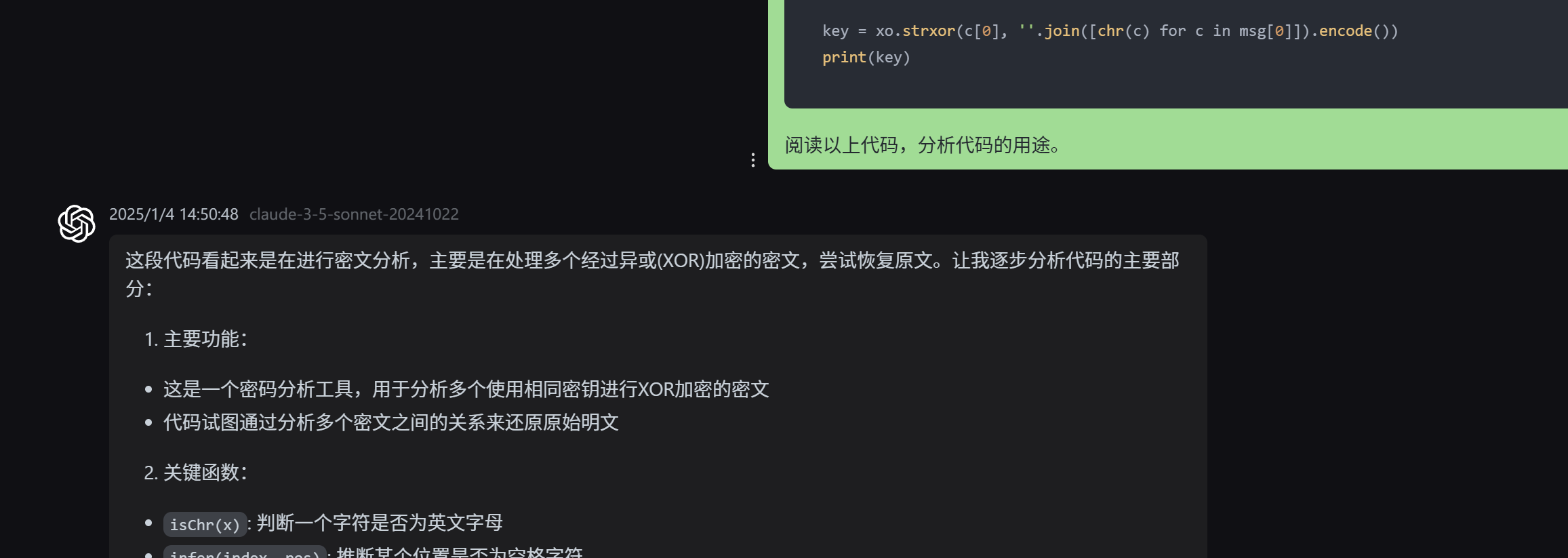
笔者此前一直使用第三方 webui,配合中转商提供的 LLM 接口。从早年的文章中选一段代码,要求 LLM 分析其用途:
但我们这次显然必须编程调用 LLM。最简单的方法是使用各家的 sdk,以 openai 为例:
pip install openai代码:
from openai import OpenAI
import os, dotenv
from rich import print
dotenv.load_dotenv()
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=os.environ.get("OPENAI_BASE_URL")
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "世界上最高的山是哪座?",
}
],
model="gpt-4o",
)
print(chat_completion)我们获得如下结果:
ChatCompletion(
id='chatcmpl-AlsS2Msj2V7er7emeYJWZDttu5d87',
choices=[
Choice(
finish_reason='stop',
index=0,
logprobs=None,
message=ChatCompletionMessage(
content='世界上最高的山是珠穆朗玛峰。它位于喜马拉雅山脉,海拔高度约为8848米。',
refusal=None,
role='assistant',
audio=None,
function_call=None,
tool_calls=None
)
)
],
created=1735974090,
model='gpt-4o-2024-08-06',
object='chat.completion',
service_tier=None,
system_fingerprint='fp_f3927aa00d',
usage=CompletionUsage(
completion_tokens=32,
prompt_tokens=15,
total_tokens=47,
completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=0, rejected_prediction_tokens=0),
prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)
)
)然而,上述方案依赖于厂家的 sdk,切换 LLM 提供商则需要重写代码,不利于快速开发。我们最好采用 langchain 来完成任务:
pip install langchain langchain-openai代码:
import dotenv
from rich import print
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
model = ChatOpenAI(model="gpt-4o")
print(model.invoke("世界上最高的山是哪座?"))输出:
AIMessage(
content='世界上最高的山是珠穆朗玛峰(又称埃佛勒斯峰),其海拔高度约为8848米(29029英尺)。珠穆朗玛峰位于喜马拉雅山脉的中尼边境。',
additional_kwargs={'refusal': None},
response_metadata={
'token_usage': {
'completion_tokens': 55,
'prompt_tokens': 15,
'total_tokens': 70,
'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}
},
'model_name': 'gpt-4o-2024-08-06',
'system_fingerprint': 'fp_f3927aa00d',
'finish_reason': 'stop',
'logprobs': None
},
id='run-8559119d-bc72-45d5-b393-2bde83191bb4-0',
usage_metadata={
'input_tokens': 15,
'output_tokens': 55,
'total_tokens': 70,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
)现在让 LLM 来阅读我们当年的脚本:
import dotenv
from rich import print
from langchain_openai import ChatOpenAI
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_core.messages import HumanMessage, SystemMessage
dotenv.load_dotenv()
model = ChatOpenAI(model="gpt-4o")
template = ChatPromptTemplate.from_messages(
[
SystemMessage("基于源码回答用户的问题。回答不超过100个字。"),
SystemMessagePromptTemplate.from_template("{code}"),
HumanMessagePromptTemplate.from_template("{question}"),
]
)
msg = template.format_messages(
code=open("exp.py").read(), question="这份代码是针对何种场景的攻击?"
)
print(model.invoke(msg))
结果:
AIMessage(
content='这段代码实现了一种针对多次一密加密(One-Time Pad)使用相同密钥的密码攻击。通过已知密文之间的异或运算,可以推测出明文中的空格或已知字符,从而恢复加密密钥。',
additional_kwargs={'refusal': None},
response_metadata={
'token_usage': {
'completion_tokens': 59,
'prompt_tokens': 461,
'total_tokens': 520,
'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}
},
'model_name': 'gpt-4o-2024-08-06',
'system_fingerprint': 'fp_f3927aa00d',
'finish_reason': 'stop',
'logprobs': None
},
id='run-7be5b763-c4f3-40d0-acac-0f006ef686be-0',
usage_metadata={
'input_tokens': 461,
'output_tokens': 59,
'total_tokens': 520,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
)0x02 上下文长度
我们现在已经可以拼接 prompt,让 LLM 分析小规模代码了。目前主流的 LLM,上下文长度是 128k token,对比最早的 GPT 3.5 的 4k 上下文数量已经是飞跃,然而,很多时候,128k 也不足以装下整个项目的全部源码。openai 官网有一个在线的 tokenizer 工具,可以帮我们评估 token 消耗:

图中可见,1345 字节的源码,被分为了 420 个 token。而对于中文字符,《红楼梦》第一章大约 6973 字,对应 6766 个 token,大约每个字对应 0.97 个 token。《红楼梦》全文大约 73.1 万字,对应 709.3k token,大约需要 5.5 个上下文窗口才能存下。笔者另外做了一些实验,见下表:
| 文件类型 | 来源 | 行数 | 词数 | 字节数 | token 数 | 字节/token | token总量÷128k |
|---|---|---|---|---|---|---|---|
| .c | afl-fuzz.c | 8197 | 26689 | 209610 | 60228 | 3.48 | 0.47 |
| .c | sqlite3.c | 260493 | 1180464 | 9195458 | 2717612 | 3.38 | 21.23 |
| .h | sqlite3.h | 13583 | 96965 | 651186 | 159298 | 4.09 | 1.24 |
| .py | dotenv/main.py | 373 | 1184 | 11692 | 2691 | 4.34 | 0.02 |
| .js | jquery.min.js | 2 | 1262 | 87533 | 30480 | 2.87 | 0.24 |
wc text.txt,token 数的统计方法是 python -c 'import tiktoken; enc = tiktoken.encoding_for_model("gpt-4o"); print(len(enc.encode(open("text.txt").read())))' 。我们发现,对于不同的编程语言,每 token 对应的平均字节数有显著差异。另外,可以想见,由于不同开发者采用不同的代码风格,即使是同一种语言,字节/token 指标也会有区别。我们在后续的粗略分析中,取「每 4 个字节消耗一个 token」比较合适。
Suricata 的代码量,若仅计 src 目录下的 .c 和 .h 文件(占大头的 rust 等其他文件不计),使用 wc 工具,可以统计出 467269 行、14988511 字节。估计 token 数量 3747k 个,需要占用 29.27 个 128k 窗口。因此,我们不可能把所有代码都交给 LLM,必须有所选择。
0x03 初识 RAG
一个最直观的想法就是:当用户要求解释某段代码的时候,我们去找出所有与这段代码相关的代码片段,与用户的问题一并提交给 LLM。这就是 RAG(Retrieval Augmented Generation,检索增强生成)技术。
回顾「以图搜图」技术:我们有一个图片库,给库中的每张图片计算 embedding 向量,存到数据库中。现在想要搜索一张新图片,则求出新图片的 embedding,在向量库中寻找与之最接近的向量,作为搜索结果。这一套方案之所以可行,是因为如果两张图片比较相似,则它们的 embedding 向量会比较接近。现在,RAG 技术需要在知识库中寻找与用户 input 相关的那些数据,也可以用相似的方案——给每条知识文本求出 embedding 向量,存进数据库;用户提问时,把用户的 input 也求出 embedding 向量,在数据库中寻找与之接近的向量,从而,我们便从知识库中匹配到了与问题相关的那些知识文本。
接下来,有两个工程问题要解决:一是如何把很长的文本分成块,二是如何快速查询最近的向量。后者很简单,现成的 pgvector 等向量数据库自带了这个功能。至于前者,我们一般把文本每 $n$ 个字符分为一块,不过,如果直接分块,会严重切断上下文信息,因此我们一般会让相邻的两个块之间,有重叠的部分。以《红楼梦》第二章为例:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
docs = TextLoader('rock.txt').load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
splits = splitter.split_documents(docs)
splits
# [0] 《红楼梦》 第二回 贾夫人仙逝扬州城\u3000冷子兴演说荣国府
# [1] 却说封肃听见公差传唤,忙出来陪笑启问...
# 那日偶又游至维扬地方,闻得今年盐政点的是林如海。这林如海姓林名海,表字如海,乃是前科的探花...
# 今如海年已五十,只有一个三岁之子,又于去岁...
# [2] 点的是林如海。这林如海姓林名海,表字如海,乃是前科的探花...
# 且说贾雨村在旅店偶感风寒,愈后又因盘费不继,正欲得一个居停之所...现在,我们手头有 8 个切片,各自用 openai 的 text-embedding-3-small 模型求出 embedding 向量,存进内存数据库中:
from langchain_openai import OpenAIEmbeddings
emb = OpenAIEmbeddings(model="text-embedding-3-small")
emb.embed_query(splits[0].page_content)
# [0.01772620901465416, -0.011474658735096455, -0.02861153520643711, ...
from langchain_core.vectorstores import InMemoryVectorStore
db = InMemoryVectorStore(emb)
db.add_documents(documents=splits)
# ['e078b8f8-91da-41ce-b74d-713726f636dd', '696c7f80-7f4f-46e5-bd1f-99fc4a1d12c4', ...现在,可以对 db 进行搜索:
db.similarity_search_with_score('林如海', k=3)
# 0.4198 却说封肃听见公差传唤...闻得今年盐政点的是林如海...
# 0.3502 点的是林如海。这林如海姓林名海...一面说一面让雨村同席坐了,另整上酒肴来...
# 0.2681 《红楼梦》 第二回 贾夫人仙逝扬州城\u3000冷子兴演说荣国府代码中的 db.similarity_search_with_score() 是 k-近邻搜索,用参数 k 指定返回的切片数量。可以看到,包含「林如海」关键字的切片被检索了出来。
text-embedding-3-small 一次能编码的 token 数量是 8191 个,维度是 1536,价格 $0.020 / 1M tokens。注意此模型的 tokenizer 是 cl100k_base 而不是 GPT-4o 使用的 o200k_base,不过 embedding 模型只需要保证「语意相似的句子的 embedding 向量也相近」即可,不必在意它具体采用哪个 tokenizer。0x04 向量数据库 pgvector
既然需要持久化保存数据,我们就不能依赖于内存数据库。开源社区有许多专业的向量数据库,但笔者比较熟悉 postgresql,故选择 pgsql + pgvector 插件来完成此项任务。用以下 compose 文件启动:
version: '3'
services:
db:
image: pgvector/pgvector:pg17
restart: always
ports:
- 5432:5432
volumes:
- ./data/:/var/lib/postgresql/data/
environment:
- TZ=Asia/Shanghai
- PGTZ=Asia/Shanghai
- POSTGRES_PASSWORD=**********
- POSTGRES_DB=chatcode
adminer:
image: adminer
restart: always
ports:
- 5433:8080
pgadmin:
image: dpage/pgadmin4
restart: always
ports:
- 5434:80
environment:
- PGADMIN_DEFAULT_EMAIL=************
- PGADMIN_DEFAULT_PASSWORD=**********
测试一下:
from langchain_postgres import PGVector
db = PGVector(
embeddings=emb,
collection_name="my_docs",
connection=os.environ['PGSQL_URI'],
)
db.add_documents(documents=splits)
db.similarity_search_with_score('林如海', k=3)返回的三个切片与内存数据库一致。观察 pgsql 数据库,出现了 langchain_pg_collection 和 langchain_pg_embedding 两个表:

collection 表内,每行有 uuid 和 name 字段:

embedding 表内容如下:

可见,langchain_postgres.PGVector 会通过 collection_id 区分不同的向量集合,从而在两张 pgsql 表中存储多个集合——例如,一套集合保存《红楼梦》切片,另一套集合保存《西游记》切片。
0x05 借助 RAG 阅读 Blueberry-CTF 代码
至此,我们已经整理出了技术步骤:
- 载入代码,切片,存进数据库
- 查询时,在数据库中找 k 个最接近的,与用户 prompt 合并,发送给 LLM
不过,我们有一些参数可能需要调整——例如,分块大小、块间重叠大小、查询时使用多少条切片。直接把 Suricata 项目作为 demo 不太明智,因为 Suricata 代码量太大,一方面比较耗时,另一方面成本也较高。我们选择一个更小的项目——Blueberry-CTF。它只有大约 1000 行 python 代码和 1500 行 html 模板。
使用以下代码建立 embedding 向量库:
import dotenv
import os
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import LanguageParser
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_postgres import PGVector
dotenv.load_dotenv()
docs = GenericLoader.from_filesystem(
"Blueberry-CTF-master",
parser=LanguageParser(),
suffixes=[
".py",
".html",
],
).load()
print(f"{len(docs) = }")
# len(docs) = 102
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
splits = splitter.split_documents(docs)
print(f"{len(splits) = }")
# len(splits) = 211
emb = OpenAIEmbeddings(model="text-embedding-3-small")
db = PGVector(
embeddings=emb,
collection_name="bbctf",
connection=os.environ["PGSQL_URI"],
)
db.add_documents(documents=splits)pgsql 可以看到 211 条数据:

现在来实现 bot:
import dotenv
import os
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_postgres import PGVector
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
dotenv.load_dotenv()
emb = OpenAIEmbeddings(model="text-embedding-3-small")
db = PGVector(
embeddings=emb,
collection_name="bbctf",
connection=os.environ["PGSQL_URI"],
)
prompt = input("> ")
code = db.similarity_search_with_score(prompt)
# print(code)
model = ChatOpenAI(model="gpt-4o")
template = ChatPromptTemplate.from_messages(
[
SystemMessage(
"你是编程专家,你会被提供一些代码片段,基于这些代码回答用户的问题。如果找不到关联的代码,则回答不知道。"
),
SystemMessagePromptTemplate.from_template("{code}"),
HumanMessagePromptTemplate.from_template("{question}"),
]
)
chain = template | model | StrOutputParser()
print(chain.invoke({"code": code, "question": prompt}))
对它提问:
> 动态 flag 是如何生成的
动态 flag 是通过 `gen_flag` 函数生成的。这个函数使用 AES 加密算法中的 ECB 模式。具体步骤如下:
1. 使用环境变量 `FLAG_GEN_KEY` 作为密钥初始化 AES 加密引擎。
2. 将字符串 `'BerryCTF'` 与用户 ID (`uid`) 和任务 ID (`tid`) 打包成字节数据。
3. 使用 AES 加密引擎加密这些字节数据。
4. 将加密后的结果转换为十六进制字符串,并格式化为 `flag{...}` 的形式返回。
```python
def gen_flag(tid, uid):
engine = AES.new(os.getenv("FLAG_GEN_KEY").encode(), AES.MODE_ECB)
plaintext = b'BerryCTF' + struct.pack('II', uid, tid)
ciphertext = engine.encrypt(plaintext)
return 'flag{' + ciphertext.hex() + '}'
```> 如何计算动态分值
根据提供的代码片段,动态分值的计算方式如下:
```sql
CASE
WHEN score_calc_type=1 THEN ROUND(pow(0.5, LEAST(2.0, GREATEST(cnt-1, 0)/(1.0*(SELECT * FROM decay_lambda)))) * base_point)
ELSE base_point
END
```
这是一个SQL语句片段,表示如果 `score_calc_type` 为 1(即动态分值),则分值是根据一个指数衰减公式计算的。具体来说:
1. 使用 `pow(0.5, ...)` 来实现指数衰减。
2. `LEAST(2.0, GREATEST(cnt-1, 0)/(1.0*(SELECT * FROM decay_lambda)))` 确保衰减指数在一定范围内。
3. `base_point` 是基础分数,动态分值是基础分数乘以衰减因子。
这意味着分数会随着解题人数的增加(`cnt`)而减少。> 后端是如何调度容器的?
后端通过一个名为 `handle_launch_request` 的函数来调度容器。以下是调度过程的主要步骤:
1. **从数据库获取待处理请求**:在 `handle_launch_request` 函数中,首先从数据库中查询所有状态为 `pending` 的实例请求。
2. **获取问题和用户信息**:对于每个待处理请求,获取对应的 `problem_id` 和 `user_id`。
3. **获取 Docker 配置**:从数据库中获取与问题 ID 关联的 Docker 配置信息。
4. **生成环境变量**:根据任务信息生成环境变量,其中包括为每个任务生成一个特定的 FLAG。
5. **启动容器**:调用 `start_container` 函数来启动容器,并传入生成的配置、问题 ID 和用户 ID。`start_container` 函数负责设置容器的名称、分配端口、设置 CPU 限制等,并最终调用 Docker 客户端启动容器。
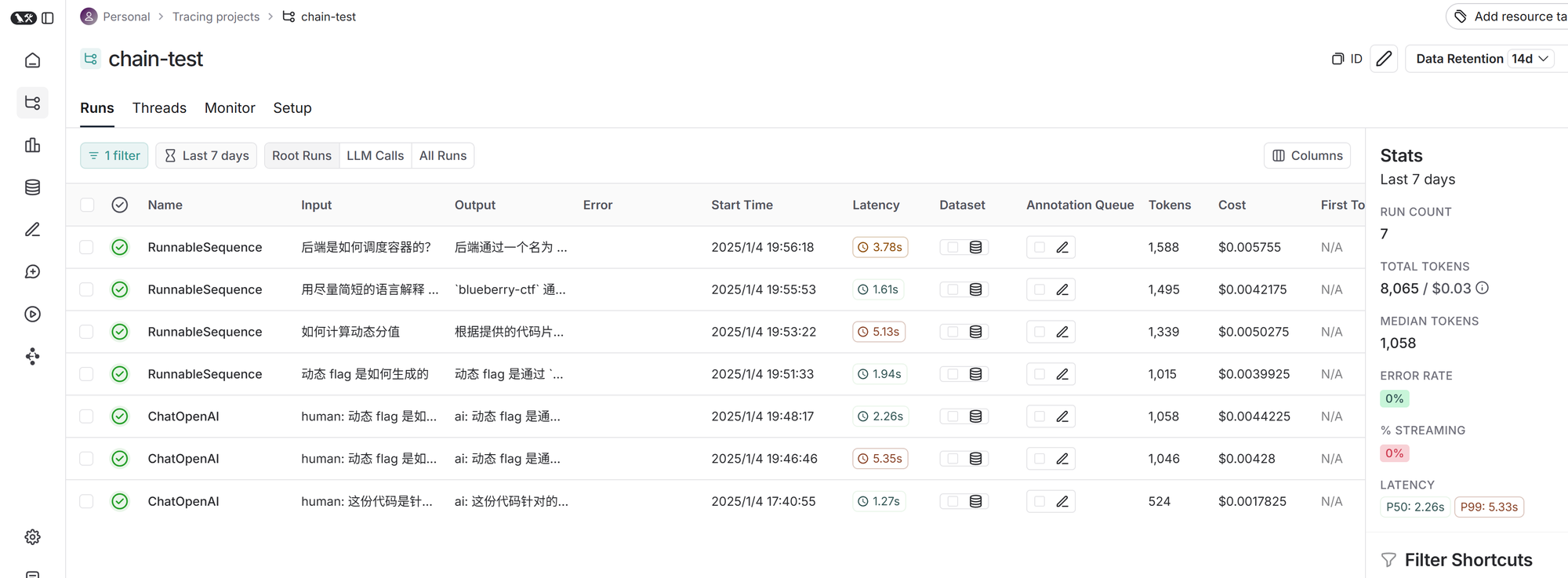
通过这些步骤,后端系统能够根据用户请求和问题配置动态调度和管理容器。这些回答都很准确,我们的实验成功了。如果使用 langsmith,我们能看到追踪信息,这对调试很有帮助:

0x06 迈向 agent
虽然我们已经实现了 RAG,但有几个不足之处:首先,无论用户询问什么问题,bot 都会查询数据库,但有时这是不必要的——如果用户问「世界上最高的山是哪座」,显然 bot 无需去分析代码。其次,这个 bot 只能看到 RAG 流程提供给它的那些代码片段,如果 bot 对代码片段存有疑虑,想要看某个文件的完整源码,也无法实现。
想要解决上述问题,我们需要抽象出两个「工具」:
- RAG 工具。bot 可以指定一段字符串,在数据库中查询相关内容
- 源码获取工具。bot 可以指定一个文件名,获取其全文
使用 langchain 提供的 @tools 装饰器,编写 RAG 工具:
from langchain_core.tools import tool
@tool
def search_db(query: str) -> list[Document]:
"""在数据库中检索 query 字符串,获取相关文本、所属文件"""
return db.similarity_search(query, k=4)
search_db.invoke({'query': 'hmac'})
编写源码获取工具:
@tool
def get_file_content(path: str) -> str:
"""读取位于 path 的文件,获得内容"""
with open(path, encoding='utf8') as f:
return f.read()
get_file_content.invoke({'path': 'Blueberry-CTF-master\\web\\util\\flag_check.py'})
最后,把这两个工具绑定给 LLM。我们使用 langgraph 自带的 ReAct agent,让 LLM 自行决定需要如何调用工具:
from langgraph.prebuilt import create_react_agent
model = ChatOpenAI(model="gpt-4o")
graph = create_react_agent(model, tools=[search_db, get_file_content])
graph生成的状态机如下:

完整代码:
import dotenv
import os
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_postgres import PGVector
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
dotenv.load_dotenv()
emb = OpenAIEmbeddings(model="text-embedding-3-small")
db = PGVector(
embeddings=emb,
collection_name="bbctf",
connection=os.environ["PGSQL_URI"],
)
@tool
def search_db(query: str) -> list[Document]:
"""在数据库中检索 query 字符串,获取相关文本、所属文件"""
return db.similarity_search(query, k=4)
@tool
def get_file_content(path: str) -> str:
"""读取位于 path 的文件,获得内容"""
with open(path, encoding="utf8") as f:
return f.read()
model = ChatOpenAI(model="gpt-4o")
graph = create_react_agent(model, tools=[search_db, get_file_content])
res = graph.invoke(
{
"messages": [
SystemMessage(
"你是程序分析员,现在用户有一些问题要问,你可以查询代码数据库(会返回与 query 相似的字符串,以及它所在的文件路径),你也可以直接阅读文件。"
),
HumanMessage("找到负责管理容器的那份代码,并返回给我最后 10 行"),
]
}
)["messages"]
print(res)
# 负责管理容器的代码在 `Blueberry-CTF-master\web\backend.py` 文件中。以下是该文件的最后 10 行代码:
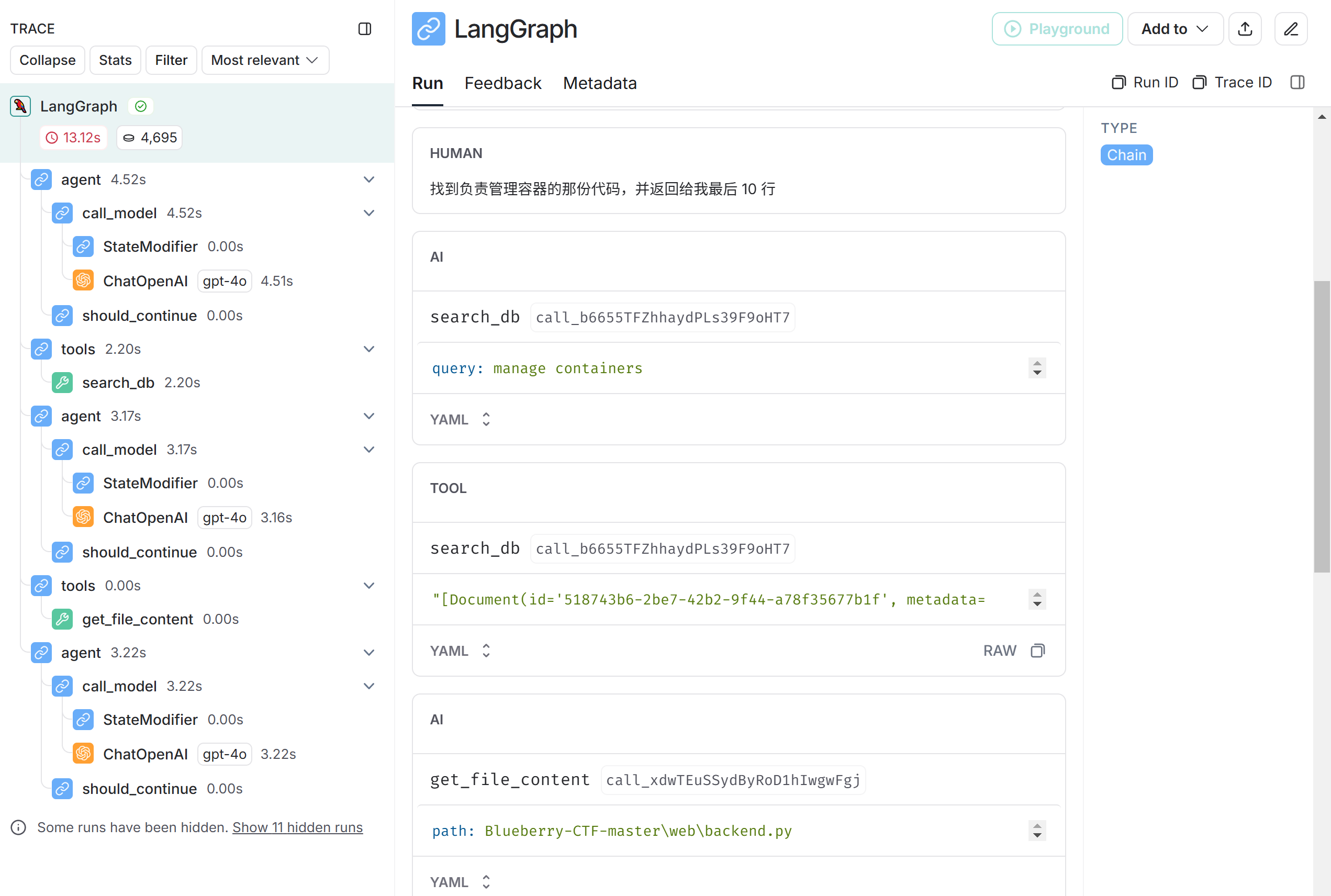
# ...现在我们实现了需求。用 langsmith 可以观察到 agent 执行过程。
0x07 下一步工作
这份 agent 代码还需要完善(例如,加入一些错误处理逻辑;控制总 token 数量,避免读一份文件就超过 128k)。笔者将在阅读 Suricata 源码的同时,不断改进 agent。
按照项目中的 .c 和 .h 文件估计,Suricata 大约会产生 25000 个切片(排除掉 test 代码之后会更少),即 25M tokens。生成 embedding 向量库的成本大约是 0.5 USD,算是非常廉价;也可以使用本地的 BGE-M3 模型。不过,在查询阶段,如果把 128k 的上下文长度都用满,则每次 GPT-4o 查询的成本是 0.32 USD,这仅计算了输入 token 成本,未计输出 token。笔者可能会改用 Deepseek-V3 模型,成本大约是 GPT-4o 的 1/9,但上下文长度只有 64k。
目前 agent 获知文件名的唯一方式是先用关键字查询数据库。然而,每次查询只会返回 k 个结果,这导致 agent 可能不知道有其他相关文件。我们可以考虑把源码文件树也输入给 agent,由 agent 从文件名判断是否需要读取。