

事情起源于笔者 2019 年的一篇文章:

文中提到,注入恶意对象引发 RCE 之后,常常由于返回的反序列化对象不符合业务代码的预期,造成程序 crash。解决方案是使用 POP 指令码(字节码是数字 0)把恶意对象弹出,再压一个正常的对象进去,这样 pickle.dumps 返回的就是普通的对象,以达成无副作用 RCE 的目的。如下图所示:
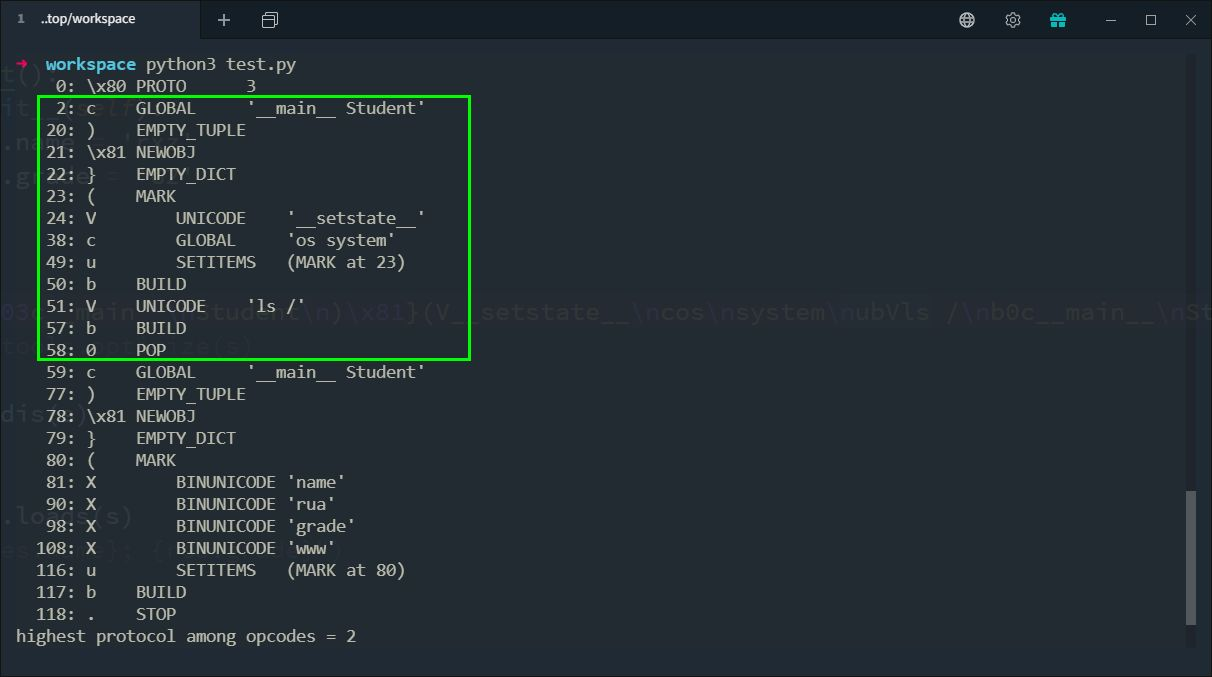
然后今天收到私信,问 POP 这个指令码有什么用。
这个问题笔者当年确实没有想过。今天翻了一下源码,发现 POP 指令主要是为了防止无限递归构造对象的。下面我们根据 pickler 源码进行说明。
0x00 Unpickler 对 POP 的处理方式
首先,我们知道 Unpickler 是一个图灵完备的虚拟机。它的指令编码方式如下:先是一个字节的 op code,然后紧跟操作数。至于操作数的表示方式,也是首先用一个字节表示类型,然后紧跟着操作数。这个虚拟机的语言大体上是一个 LL(0) 型文法,所以 Unpickler 仅通过简单地重复执行「读入一个字节的操作数 - 调用对应 handler」,就可以完成反序列化工作。
Unpickler 每次读入操作数,就查表找到 handler 并调用,handler 会吃掉一些字符,构造一个对象或进行其他操作。具体的 pickle 虚拟机操作码、Unpickler 工作方式可以去我的知乎文章查看。
POP 操作码对应的 op code 是 0,注释是 discard topmost stack item。

乍一看,这个 POP 指令确实没啥用处。如果我先将一些对象压入栈,再弹出去,那我何不当初就不把这些对象压栈呢?抱着这样的疑问,笔者重新阅读了 Pickler 的源码,看看什么情况下会产生 POP 这个指令。
0x02 Pickler 何时会产生 POP 指令
查找产生 POP 指令的代码,一共有三处,分别是 save_reduce、save_tuple、save_frozenset 方法。
由于 reduce 是用于储存 __reduce__ 方法,比较特殊,我们先看平凡的 save_tuple 方法在何时产生 POP 指令:
def save_tuple(self, obj):
if not obj: # tuple is empty
if self.bin:
self.write(EMPTY_TUPLE)
else:
self.write(MARK + TUPLE)
return
n = len(obj)
save = self.save
memo = self.memo
if n <= 3 and self.proto >= 2:
for element in obj:
save(element)
# Subtle. Same as in the big comment below.
if id(obj) in memo:
get = self.get(memo[id(obj)][0])
self.write(POP * n + get)
else:
self.write(_tuplesize2code[n])
self.memoize(obj)
return
# proto 0 or proto 1 and tuple isn't empty, or proto > 1 and tuple
# has more than 3 elements.
write = self.write
write(MARK)
for element in obj:
save(element)
if id(obj) in memo:
# Subtle. d was not in memo when we entered save_tuple(), so
# the process of saving the tuple's elements must have saved
# the tuple itself: the tuple is recursive. The proper action
# now is to throw away everything we put on the stack, and
# simply GET the tuple (it's already constructed). This check
# could have been done in the "for element" loop instead, but
# recursive tuples are a rare thing.
get = self.get(memo[id(obj)][0])
if self.bin:
write(POP_MARK + get)
else: # proto 0 -- POP_MARK not available
write(POP * (n+1) + get)
return
# No recursion.
write(TUPLE)
self.memoize(obj)我们看这一段长注释:
这里有一个细节。当调用save_tuple时,id(obj)肯定不在memo中。
(笔者注:如果id(obj)在memo中,那么 Pickler 会选择生成GET指令码,让 Unpickler 直接从memo取出并压栈,而不是选择调用save_tuple(self, obj)生成构造 tuple 的指令序列,让 Unpickler 重新构建对象)
从而,可以推断出obj是在本函数执行的过程中,已经被构造出来,并放进了memo的。而现在我们又要构造一次obj,显然是产生了递归。
所以,现在应该把当前栈里的东西弹空,并要求 Unpickler 直接引用memo中的实例,作为这个 tuple 反序列化的结果。
注释写得非常清楚明了,笔者也刷新了自己对 memo 的认识:memo 不仅可以帮助 Unpickler 复用对象,还可以用于防无限递归!当检测到对象递归时,Pickler 会通过 POP 放弃自己在栈中生成的中间对象,并提示 Unpickler 采用 memo 中已经构造好的实例。
那么我们很容易构造一个对象,使得 Pickler 产出 POP 指令:
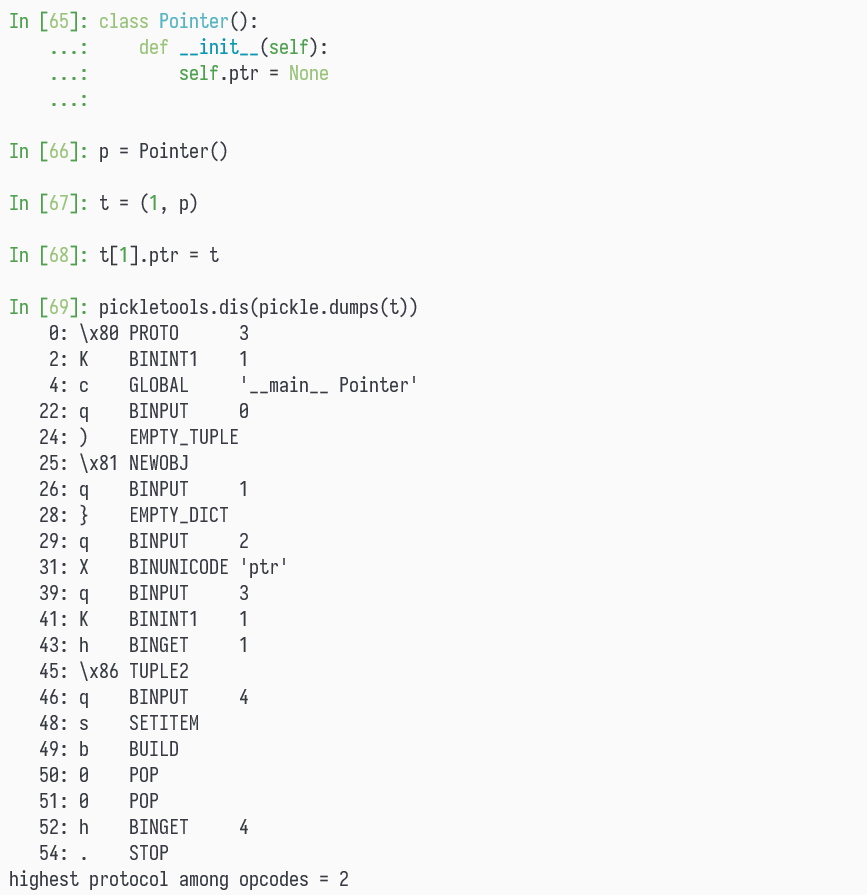
逐行解释一下指令序列。
- pickle protocol 是 version 3
- 压入一个整数
1 - 压入
__main__.Pointer,注意这是 class 而非 instance,接下来要实例化这个类 - 将栈顶元素存进
memo[0](这是一个无用的 PUT) - 压入一个空的 tuple
- 以栈顶那个空的 tuple 作为参数,实例化栈内第二个元素(即
Pointer类)。
完成后,栈顶是一个初始的Pointer对象,栈里面第二个元素是个整数1 - 把栈顶元素(即这个
Pointer对象)存进memo[1] - 压入一个空的 dict
- 将栈顶元素存进
memo[2](这是一个无用的 PUT) - 压入字符串
"ptr" - 将栈顶元素存进
memo[3](这是一个无用的 PUT) - 压入一个整数
1 - 将
memo[1]压栈(即将刚刚的 Pointer 对象压栈) - 弹出栈顶两个元素组成 tuple,压入栈
现在的栈顶元素是(1, memo[1], ),栈内第二个元素是字符串"ptr",第三个元素是个空的 dict,第四个元素是一个Pointer实例,即memo[1]。最底下是一个整数1 - 将栈顶元素存进
memo[4],即memo[4] = (1, memo[1], ) - 依次弹出栈中的键、值,组装 dict
这条指令完成后,栈顶是{"ptr": (1, memo[1], )},栈内第二个元素是一个Pointer实例(即memo[1]),最底下是一个整数1 - 以栈顶 dict 的键值对,去修改栈内第二个对象的属性。内部是调用
setattr来修改对象属性
指令完成后,栈顶是一个Pointer实例,memo[1]指向它。这个Pointer对象的ptr属性被设为memo[1],即这个Pointer自身。栈底是整数1 - POP,丢弃掉栈顶
- POP,丢弃掉栈顶,现在栈里面啥都不剩了
- 将
memo[4]压入栈,成为栈中唯一的元素 - 将栈顶返回,作为反序列化结果
最终,返回的结果是 memo[4] ,即 (1, memo[1], ) ,而 memo[1] 是一个 Pointer 对象,其 ptr 指向这个 Pointer 本身。可见最终 Unpickler 返回的对象正是我们所需要的。
至此,我们解决了「何时会产生 POP 指令」这一问题。
0x03 进一步思考:为什么 Pickler 不优化指令序列
一般情况下,Pickler 会将每个中间对象都存进 memo,所以指令序列中往往存在大量的 PUT,但这大部分的 PUT 都不会被 GET 引用,可以安全地删去。另外,上文讨论过,如果产生了 POP 指令,说明肯定有一些压栈步骤是无效的,也应该可以抵消。那么,Pickler 为什么不做这些优化呢?
下面我们分别讨论「删去无用 PUT」和「抵消 POP」这两种优化是否能实现。
在设计上,Pickler 被考虑需要用于序列化非常大的对象(实践上也确实如此,PyTorch、NumPy 的导入导出便是采用了 pickle 来序列化动辄几个 GB 的对象)。Pickler 是将生成的指令序列写到一个 buffered file 里面( pickle.dumps 是采用 io.BytesIO 这个 file-like 对象),且边构造边写入。
Pickler 对 file 的使用非常克制,一共只使用到了 write 这一个方法,连 output buffer 都是通过自己实现 _Framer 来完成。笔者认为,这证明 pickle 的设计者希望各种各样「可写入字节流的对象」都可以用于 Pickler,例如本地文件、BytesIO、stderr 流,甚至是 socket 对象。
在这个基础上,能不能让 Pickler 实现「删去无用的 PUT 指令」呢?显然不可以,因为不是所有支持 write 的东西都支持重新写入,例如 socket 对象就不能重新写。退一步讲,即使支持了重新写入,把文件重写一遍也要付出不少的代价,且对 Unpickler 而言收益有限。
因此,pickle 放弃了在 Pickler 中进行「删去无用 PUT」这一优化,而是让用户采用 pickletools.optimize() 来对较小的 pickle 指令序列进行这个优化。
接下来讨论是否能实现「抵消 POP」这个优化。笔者认为,是性能原因阻碍了这个优化的实现。「发现递归的存在性」是简单的,但是「生成等效的简化指令序列」并不是一个轻松的工作。递归很可能不是像本文中这个例子一样引用自身,而是 A->B->C->D->A 这样很长的链条。尽管我们可以建立依赖图、给出最优构造,但这是一个很复杂且耗时的工作。事实上递归很少见,即使优化了 POP 也得不到很显著的 Unpickler 性能提升,故 pickletools.optimize() 不进行此类优化。
总结一句:这两个优化在理论上都可以做,但是考量泛用性和性能之后,pickle 的设计者决定默认不做。用户可以通过 pickletools.optimize() 做「删去无用 PUT」优化,而「抵消 POP」这个优化并未提供。