

0x00 前言
MCP 是 Anthropic 于去年 11 月发布的协议。它的目标是成为 LLM 领域的 usb 标准,将 LLM 与应用系统连接起来。现在,MCP 的生态正在蓬勃发展,cloudflare 昨天发布了 MCP 服务部署指引,cherry studio 也于上周完善了 MCP 协议支持,百度地图更是于上周开源了官方的 MCP 服务端程序。我们可以越来越清晰地看到,LLM 发展到今年,必然需要一个通用的协议去与外部系统交互(如同 gRPC 之于传统应用),以简化 workflow 和 agent 开发,而 MCP 目前是生态最佳的协议,有大量开源的 server 和 client 程序,极有可能成为未来的事实标准。
在介绍 MCP 之前,笔者想先与读者一起复盘一场开发经历。上月初,笔者开始着手编写一个“调研报告生成器”,它的主要任务如下:用户提供一个主题,它去网络上搜索相关资料,把找到的文本整合起来,输出大约一万字的调研报告。这项任务略类似于 deep research,但我们的应用场景不是面向学术研究的,且需要自行指定各个章节的格式。
笔者快速实现了 v1 版本,即原型版本。它是一个 workflow:
- 由 DeepSeek-V3 根据研究主题,生成 10 个用于搜索的关键词组,每个关键词组包含 3 个关键词;
- 使用 browser-use 工具(底层模型是 gpt-4o-mini)控制浏览器,去 Google 搜索上述关键词,并记录搜到的 url。每个关键词组会搜到大约 10 个结果,故本步骤产出大约 100 个 url;
- 用 selenium 访问上述 url,等待 15s 让页面加载完毕,然后保存 html,并使用 html2text 工具转为 markdown 文本(平均长度 12600 token);
- 上述文本中存在大量非正文内容(例如页面框架、广告等),使用 Doubao-1.5-pro 予以清洗,仅保留正文文本。本步骤产出 100 篇清洗后的文本,平均长度 5000 token;
- 针对每篇文献,用 Doubao-1.5-pro 生成摘要。平均摘要长度 360 token;
- 将所有摘要(大约共计 36k token)输入给 DeepSeek-R1,要求它生成 3 个章节标题,并给每个章节指派 4 篇文献;
- 针对每个章节,将 4 篇文献输入给 DeepSeek-V3,要求它输出章节内容(大约 5000 字);
- 将上述 3 个章节的内容输入给 Claude 3.7 Sonnet,要它润色、汇总成全文、添加序言和结论,大约产出 15000 字,即为最终的调研报告。
上述每个功能都实现为一份独立的 Python 代码,通过文件系统保存数据。这对于原型系统是没问题的,好处在于调试方便,但终非长策。v2 版本重新组织了代码,用 sqlite3 保存数据,到此为止,产品基本可供其他人使用了。
开发过程中,笔者注意到几个问题:(一)系统中的 LLM 相关代码量其实很少,大部分代码都是传统业务(如操纵浏览器访问页面),这些组件完全可以独立编写、独立测试,没必要集成到 workflow/agent 项目中;(二)有些业务使用了 LLM,但 LLM 选型是固定的,输入与输出格式是固定的,例如“调用豆包进行数据清洗”。这类组件也可以独立出去;(三)可以预见,上述组件会在不同的 workflow/agent 中复用(例如,本项目需要抓取网页内容,另一个爬虫项目也需要抓取网页内容),因此本着 DRY 原则,我们应当把这些组件单独实现成微服务,暴露 API 供 workflow/agent 使用。
由此可见,我们非常迫切地需要把“与 workflow/agent 核心任务无关”的逻辑分离成微服务,给 workflow/agent 瘦身,让 workflow/agent 代码专注于推理和文本生成。于是,笔者将“抓取网页内容”等工具转为独立服务,暴露 HTTP API。另一方面,原先的 workflow 有一些本质性的缺陷:(一)搜索关键词决定了搜出的 url,搜出的 100 个 url 决定了文献质量,进而决定了最终报告质量。然而,搜索关键词是在最初拍脑门想的,不能按照情况改进关键词;(二)各个章节是各自独立编写的,编写第二章时,不知道第一、第三章讲了什么,因此整篇文章的各章节之间缺乏联系;(三)在 workflow 的最后一步,我们要求 LLM 直接生成 15000 字的全文,这对于 LLM 来说很困难,不能很好地执行所有约束条件。
因此,笔者决定推倒重写。v3 版本是一个 ReAct agent,它可以使用以下工具:对关键词进行搜索并获取 url 及摘要;获取指定 url 的正文内容;修改文章结构(例如新增一个段落或修改章节标题);覆写一个段落。每次交互时,我们把当前文章内容、行动历史、一些 cache 提供给 LLM,要求 LLM 先思考目前局面,然后要么选择一个工具执行,要么宣布报告已编写完成。
那么,我们该如何实现“让 agent 调用工具”呢?本站的前一篇文章《LLM 应用开发心得》提到过,有些 LLM 供应商提供了 function call 特性,可以直接使用;而对于其他供应商,我们可以让 LLM 输出一个包含工具参数的 xml。无论如何,我们首先需要告知模型“有哪些工具可用”。当然,模型本身是不参与工具调用的,工具调用由外部代码实现。
v3 版本是没有使用 MCP 的。但回过头来,笔者发现,MCP 其实对我们十分有用:
- 社区已经编写好大量的 MCP server,我们的 agent 只要能调用 MCP 服务,则可以省掉自己造轮子的时间。比如,调研报告生成器项目中,“调用浏览器抓取网页”这个微服务的开发过程完全可以省掉。
- MCP 统一了 server 向 LLM 暴露工具的方式。我们自行编写的微服务通过 HTTP API 提供接口,但即使是 restful API,不同的人也会设计出不同的接口。可以想见,如果每个开源项目都有自己的接口,则适配工作会相当麻烦。如果有一套世界通用的规范,则我们无需浪费时间在接入各类 API 上。
- 各种工具的描述文档,可以由 MCP server 提供,我们无需在 agent 内硬编码“这个工具是什么用途、有哪些参数”。
在本文中,我们首先学习 MCP 协议的基本概念(server、client、resource、tool 等),然后阅读一个简单 MCP server 的源码,并自己实现一个 demo。
0x01 MCP 基础结构
MCP 是一个 C/S 协议。结构如图所示:
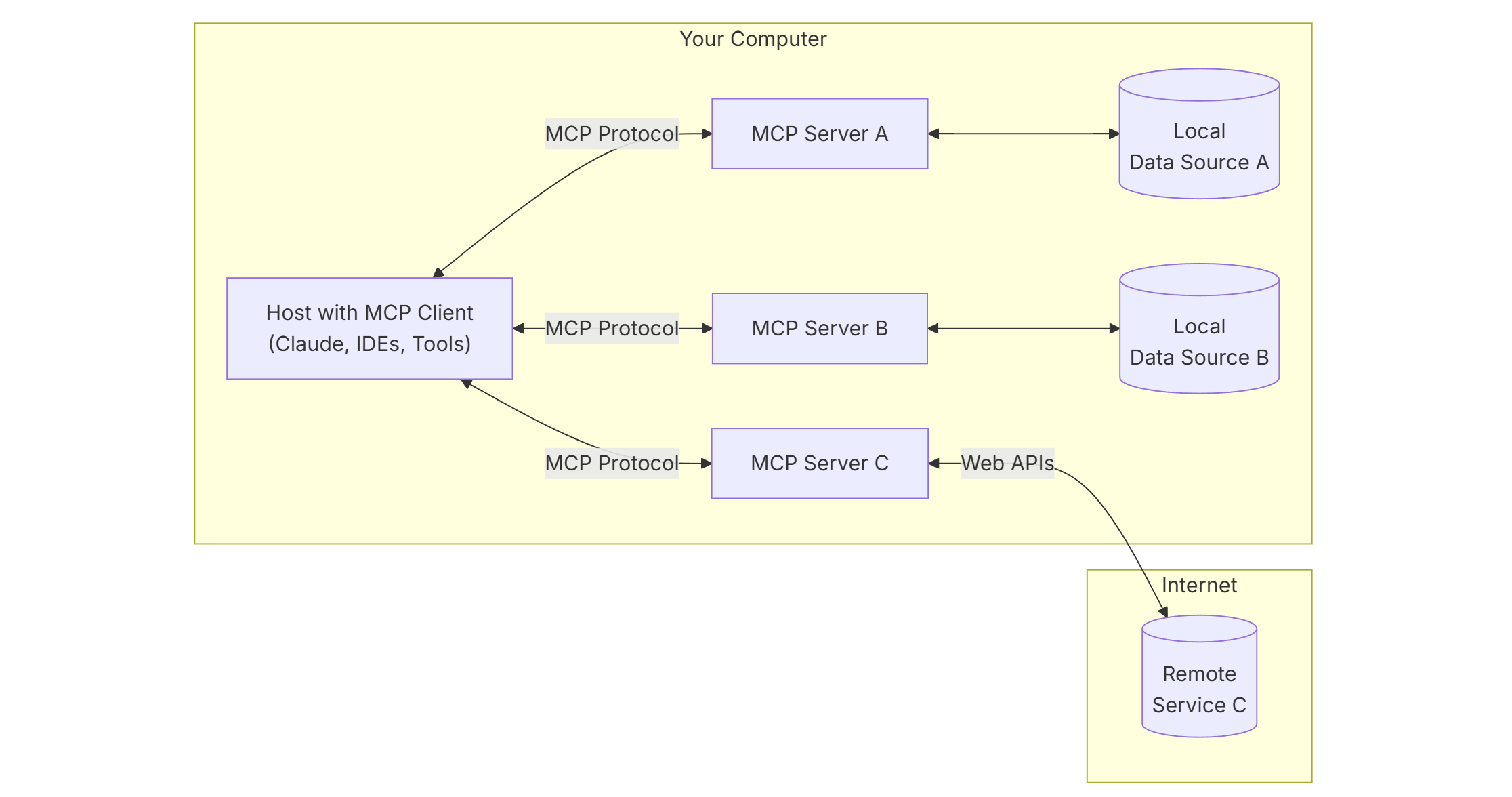
各种 LLM 应用就是 client,它会产生 MCP 请求,并发送给 MCP server;而 MCP server 有两种通讯方式:通过 stdio 通讯(即在用户电脑上运行 npx -y @modelcontextprotocol/server-postgres postgresql://localhost/mydb 这样的程序),或者通过 HTTP sse 通讯(LLM API 流式传输也是用的 sse 方案)。MCP server 目前有 TypeScript、Python、Java、Kotlin、C# 的 sdk。
无论是 stdio 通讯还是 HTTP sse 通讯,消息格式均为 JSON-RPC 2.0。信道上传输的消息分为以下四种(详细格式见文档):
Request,期望得到响应的请求;Result,对成功的Request的响应;Error,对失败的Request的响应;Notification,单向数据推送,不需要响应。
信道建立后,第一步是握手。client 发送一个 initialize request,server 返回 initialize response,client 再发送一个 initialized notification,完成握手。这个握手流程与 TCP 十分相似。接下来,双方传输消息,直到信道关闭为止。
眼见为实,我们现在来观察一场通讯。运行如下指令,启动调试器:
npx -y @modelcontextprotocol/inspector npx @modelcontextprotocol/server-filesystem C:\\Users\\neko\\Desktop\\dev\\mcp@modelcontextprotocol/inspector 是 MCP 调试器,意在为 MCP server 开发者提供一个 web ui 以帮助 debug。被调试的
@modelcontextprotocol/server-filesystem 是官方提供的一个 MCP server,它把文件系统暴露给 LLM。其他示例 server 可以在 Github 项目页找到。点击“Connect”,我们可以看到一些日志:
Stdio transport: command=C:\Windows\System32\cmd.exe, args=/C,C:\Program Files\nodejs\npx.cmd,@modelcontextprotocol/server-filesystem,C:\Users\neko\Desktop\dev\mcp
Spawned stdio transport
Connected MCP client to backing server transport
Created web app transport
Created web app transport
Set up MCP proxy
Received message for sessionId 30c34b11-6b07-4f97-a0d5-3fd354ad6eda
Received message for sessionId 30c34b11-6b07-4f97-a0d5-3fd354ad6eda现在握手完成,我们点击“List Tools”,再点击“list_directory”,要求 server 列目录:
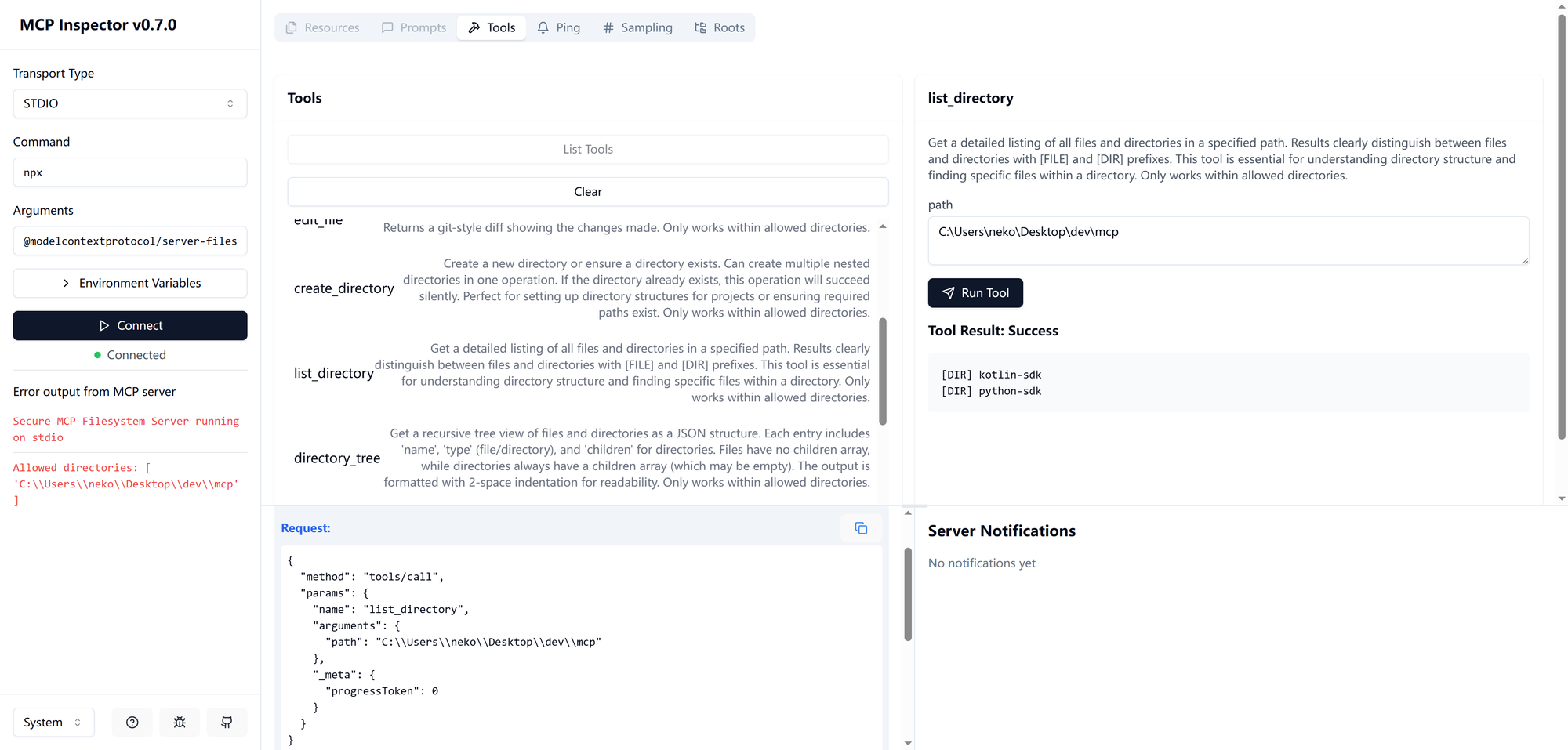
在屏幕下方,我们可以看到两轮请求。第一条 Request 是:
{
"method": "tools/list",
"params": {}
}即调用 tools/list 端点,无参数。这个 Request 获得的响应是:
{
"tools": [
{
"name": "read_file",
"description": "Read the complete contents of a file from the file system. Handles various text encodings and provides detailed error messages if the file cannot be read. Use this tool when you need to examine the contents of a single file. Only works within allowed directories.",
"inputSchema": {
"type": "object",
"properties": {
"path": {
"type": "string"
}
},
"required": [
"path"
],
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}
},
// ...
]
}上述 json 中列出了 MCP server 提供的所有 tool 的信息,包括工具名、描述、输入格式等。接下来,client 发送了列目录的请求:
{
"method": "tools/call",
"params": {
"name": "list_directory",
"arguments": {
"path": "C:\\Users\\neko\\Desktop\\dev\\mcp"
},
"_meta": {
"progressToken": 0
}
}
}服务端响应如下:
{
"content": [
{
"type": "text",
"text": "[DIR] kotlin-sdk\n[DIR] python-sdk"
}
]
}于是,我们完成了两次工具调用——第一次调用获取“服务端有哪些工具”,第二次具体调用 list_directory 工具。我们再试试发一个非法请求:
{
"method": "tools/call",
"params": {
"name": "list_directory",
"arguments": {
"path": "C:\\Users\\neko\\Desktop\\dev\\mcp\\123"
},
"_meta": {
"progressToken": 1
}
}
}这个请求要求 MCP server 列一个不存在的目录。返回报文是:
{
"content": [
{
"type": "text",
"text": "Error: ENOENT: no such file or directory, scandir 'C:\\Users\\neko\\Desktop\\dev\\mcp\\123'"
}
],
"isError": true
}此 MCP server 通过 isError 字段表示请求非法。注意这并不是 JSON-RPC 2.0 定义的错误码,即这场错误不是“系统层面的错误”而是“业务逻辑层面的错误”。MCP 在遇到系统层面错误时,会返回 JSON-RPC 2.0 错误码,如 -32700(ParseError) 等。
0x02 MCP server 提供的服务
MCP server 主要向用户提供以下几种服务:Resource、Tool、Prompt。本节将详细讨论它们。
Resource 服务
Resource 服务与 HTTP GET 请求相近,允许客户端获取一些信息,且这种读取应当是无副作用的。MCP 使用 uri 来定位资源,如 file:///home/user/documents/report.pdf 等。uri 的具体设计由开发者自行定义。Resource 内容要么是 UTF-8 文本,要么是二进制数据(以 base64 编码)。
client 可以向 server 询问“你有哪些资源”,方法是调用 resources/list 这个端点。服务端会返回资源清单,包括静态资源(uri 固定)和动态资源(uri 里面有变量)。client 通过 resources/read 端点读取资源。
server 可以发送 notifications/resources/list_changed,告知用户“资源清单有变”。client 可以通过 resources/subscribe 端点订阅某个 uri 的更新通告,当这个 uri 的资源更新时,server 会发送 notifications/resources/updated 通知 client。
Tool 服务
Tool 服务是 MCP 最核心的功能,类似于 POST,用于执行一些可以有副作用的操作。每个 tool 有自己的 name、description(可选)和输入格式。
client 可以通过 tools/list 端点列出所有工具,通过 tools/call 端点使用工具,如同前文分析的那个例子一样。与 Resource 类似,server 可以发送 notifications/tools/list_changed 表示工具清单有变。另外,工具可以在运行时添加、删除、更新。
如果工具执行期间发生了逻辑错误,则应当如同上文例子一样,将 isError 置为 true,并在 content 中描述错误详情。于是,无论成功失败,content 字段里都包含了执行结果信息,供 LLM 使用。
Prompt 服务
Prompt 服务提供了一些提示词模板,大致可以理解为“输入几个参数,按模板编造 prompt 输出”的服务。client 可以通过端点 prompts/list 获取所有 prompt 模板,用 prompts/get 端点输入参数,获取 prompt。这里的 prompt 不是单个消息,而是消息列表,例如:包含 3 个 message,role 分别为 user、assistant、user。详见文档。
Prompt 服务算是 MCP 的非主营业务,只是为开发者提供方便,避免在 agent 应用中硬编码 prompt。举个例子:假设我们针对某任务设计了一个 prompt,把它硬编码进了 n 个 agent,后来我们改进了 prompt,则需要更新这全部 n 个 agent 的代码;然而,如果 prompt 是由 MCP server 提供的,则我们只需要更新 MCP server 即可,下游的 agent 会自动获得这次 prompt 升级的收益。
另外,官方文档提到,Prompt 服务有助于 UI 集成。例如,client app 可以弹出一个框,要求用户填写几个参数,然后它把这些参数拿给 MCP server 要求组装 prompt。
0x03 MCP server 案例:pgsql 服务
接下来,我们读一遍官方 pgsql MCP server 的代码。先看看它提供了哪些服务:
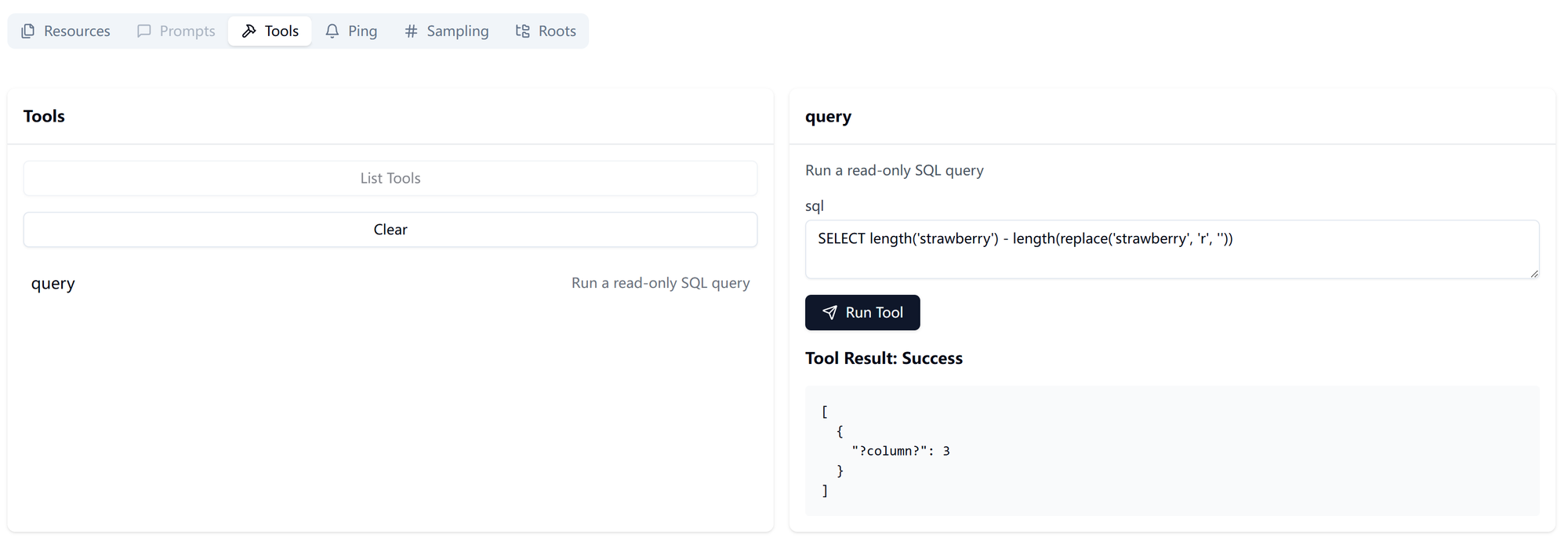
npx -y @modelcontextprotocol/inspector npx @modelcontextprotocol/server-postgres postgresql://****可以发现,它为每个表提供了一个 resource,里面是表定义;提供了一个名为“query”的 tool,可供执行任意 SQL 指令。我们发条指令,数一下 strawberry 里面有多少个 r:
观察代码。
#!/usr/bin/env node
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import {
CallToolRequestSchema,
ListResourcesRequestSchema,
ListToolsRequestSchema,
ReadResourceRequestSchema,
} from "@modelcontextprotocol/sdk/types.js";
import pg from "pg";
const server = new Server(
{
name: "example-servers/postgres",
version: "0.1.0",
},
{
capabilities: {
resources: {},
tools: {},
},
},
);这段代码是 MCP server 实例化。一个 MCP 服务会有自己的 _serverInfo(包括 name 和 version),以及 options (包括 capabilities 和 instructions)。如有兴趣,可以去看 typescript-sdk/src/types.ts 中的类型体操。
const args = process.argv.slice(2);
if (args.length === 0) {
console.error("Please provide a database URL as a command-line argument");
process.exit(1);
}
const databaseUrl = args[0];
const resourceBaseUrl = new URL(databaseUrl);
resourceBaseUrl.protocol = "postgres:";
resourceBaseUrl.password = "";
const pool = new pg.Pool({
connectionString: databaseUrl,
});
const SCHEMA_PATH = "schema";上面的代码是在准备 pgsql 连接池。
server.setRequestHandler(ListResourcesRequestSchema, async () => {
const client = await pool.connect();
try {
const result = await client.query(
"SELECT table_name FROM information_schema.tables WHERE table_schema = 'public'",
);
return {
resources: result.rows.map((row) => ({
uri: new URL(`${row.table_name}/${SCHEMA_PATH}`, resourceBaseUrl).href,
mimeType: "application/json",
name: `"${row.table_name}" database schema`,
})),
};
} finally {
client.release();
}
});上面实现了 resources/list 端点的 handler。它返回了 resource 列表,每个 resource 有 uri, mimeType, name 属性。其中 uri 和 name 是 MCP 规定必须提供的。
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
const resourceUrl = new URL(request.params.uri);
const pathComponents = resourceUrl.pathname.split("/");
const schema = pathComponents.pop();
const tableName = pathComponents.pop();
if (schema !== SCHEMA_PATH) {
throw new Error("Invalid resource URI");
}
const client = await pool.connect();
try {
const result = await client.query(
"SELECT column_name, data_type FROM information_schema.columns WHERE table_name = $1",
[tableName],
);
return {
contents: [
{
uri: request.params.uri,
mimeType: "application/json",
text: JSON.stringify(result.rows, null, 2),
},
],
};
} finally {
client.release();
}
});这段代码实现了 resources/read 端点。按照规则,resource 返回结果需要有 uri 字段,以及 text 和 blob 二者之一。这个端点可以向 client 返回多个 resource。
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: "query",
description: "Run a read-only SQL query",
inputSchema: {
type: "object",
properties: {
sql: { type: "string" },
},
},
},
],
};
});上面的代码实现 tools/list 端点。顺带一提,文档建议在 description 中举出一些该工具的应用示例。由于 description 在大部分场景下会被 LLM 阅读,故我们也需要对 description 进行提示词工程。
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "query") {
const sql = request.params.arguments?.sql as string;
const client = await pool.connect();
try {
await client.query("BEGIN TRANSACTION READ ONLY");
const result = await client.query(sql);
return {
content: [{ type: "text", text: JSON.stringify(result.rows, null, 2) }],
isError: false,
};
} catch (error) {
throw error;
} finally {
client
.query("ROLLBACK")
.catch((error) =>
console.warn("Could not roll back transaction:", error),
);
client.release();
}
}
throw new Error(`Unknown tool: ${request.params.name}`);
});这是 tools/call 工具的实现。应当注意,“使用哪个工具”不是在端点中定义的,而是在 name 字段中定义的。上面代码中,通过声明 READ ONLY 事务,保证了对数据库只读不写。
async function runServer() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
runServer().catch(console.error);
这是代码的结尾部分,将 server 通过 stdio 信道运行起来。
0x04 实现一个 MCP server
接下来,我们自行实现一个“四则运算器”服务,不过这个服务只能做二元运算:接收 op, x, y,计算 x op y 并返回。使用 Python sdk。
MCP Python sdk 的 server API 非常像 fastapi。我们的服务端实现如下:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("calc")
@mcp.tool()
def add(op: str, x: int, y: int) -> int:
"""执行一次四则运算 x op y。其中 x, y 均为整数,op 为 +, -, *, / 中的一个。"""
import operator
func = {
"+": operator.add,
"-": operator.sub,
"*": operator.mul,
"/": operator.floordiv,
}[op]
return func(x, y)
if __name__ == "__main__":
mcp.run()
使用 mcp dev calc-server.py 可以调试这个 server。现在,将这个 server 集成到 cherry studio 中:
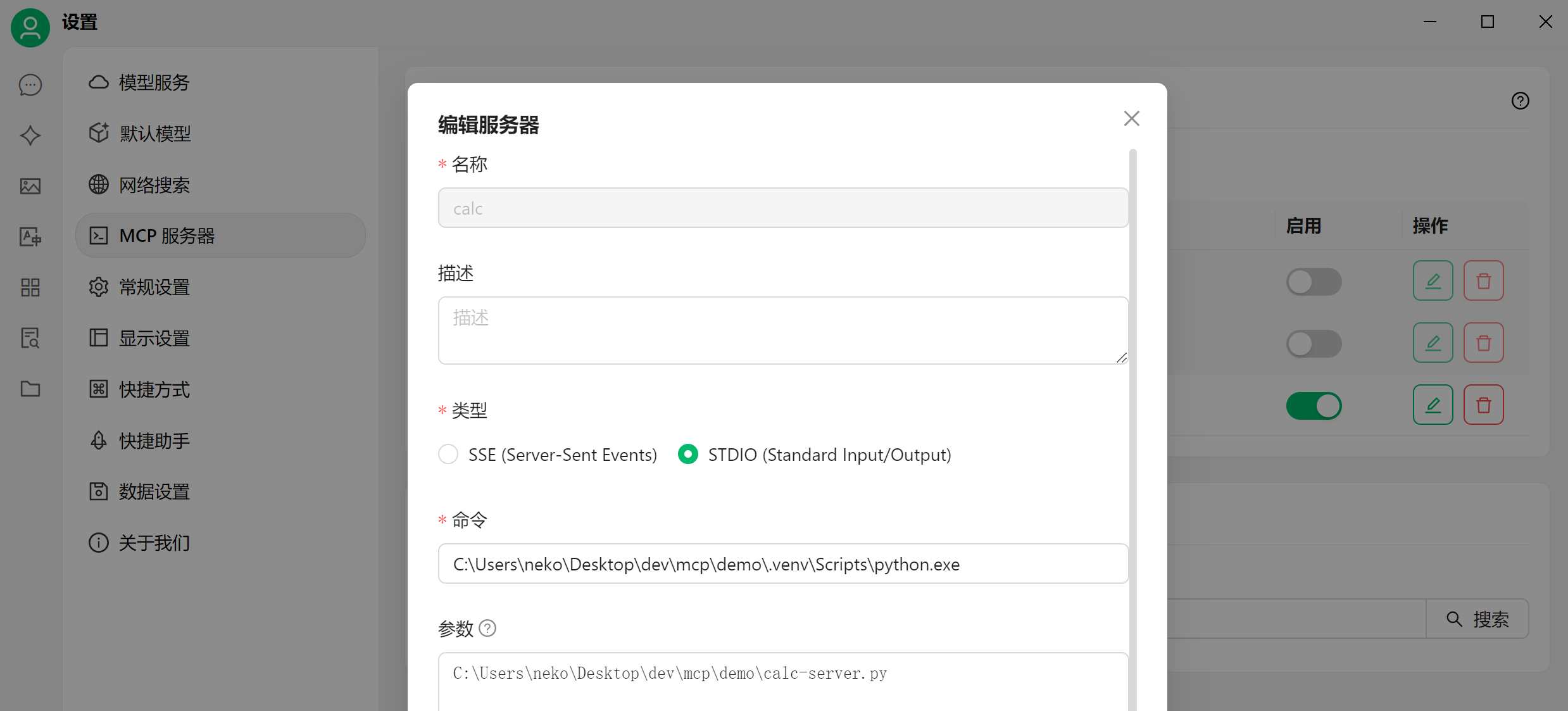
测试:
于是,我们成功接入了自己的 MCP server。