Once you complete this exercise you will know how:
- To use custom dictionaries for helping the fuzzer to find new execution paths
- To parallelize the fuzzing job accross multiple cores
In order to complete this exercise, you need to:
- Find an interface application that makes use of the LibXML2 library
- Copy the SampleInput.xml file to your AFL input folder
- Create a custom dictionary for fuzzing XML
- Fuzz LibXML2 until you have a few unique crashes. I recommend you to use as many AFL instances as posible (CPU cores)
- Triage the crashes to find a PoC for the vulnerability
- Fix the issues
0x01 环境准备
LibXML2 2.9.4 release 地址:
Release v2.9.4 · GNOME/libxml2
Release of libxml2-2.9.4
 GNOME
GNOME我们得找个使用到了 libxml2 的程序。查阅 libxml2 文档:
Home · Wiki · GNOME / libxml2 · GitLab
XML parser and toolkit


发现提供了若干 example。不过 libxml2 编译好之后,可以在 bin 里面发现 xml2-config, xmlcatalog 以及 xmllint 三个程序,我们直接使用其中的 xmllint 作为 fuzz 目标。
先编译 libxml2:
export CC=/afl/afl-clang-lto
export AFL_USE_ASAN=1
./autogen.sh
./configure --prefix=/work/out
make -j 16
make install接下来,准备输入数据:
wget 'https://raw.githubusercontent.com/Ruanxingzhi/Fuzzing101/main/Exercise%205/SampleInput.xml' -O corpus/input.xml
wget 'https://raw.githubusercontent.com/AFLplusplus/AFLplusplus/stable/dictionaries/xml.dict' -O dict/xml.dict来看怎样设置 xmllint 参数可以覆盖到最多的代码。
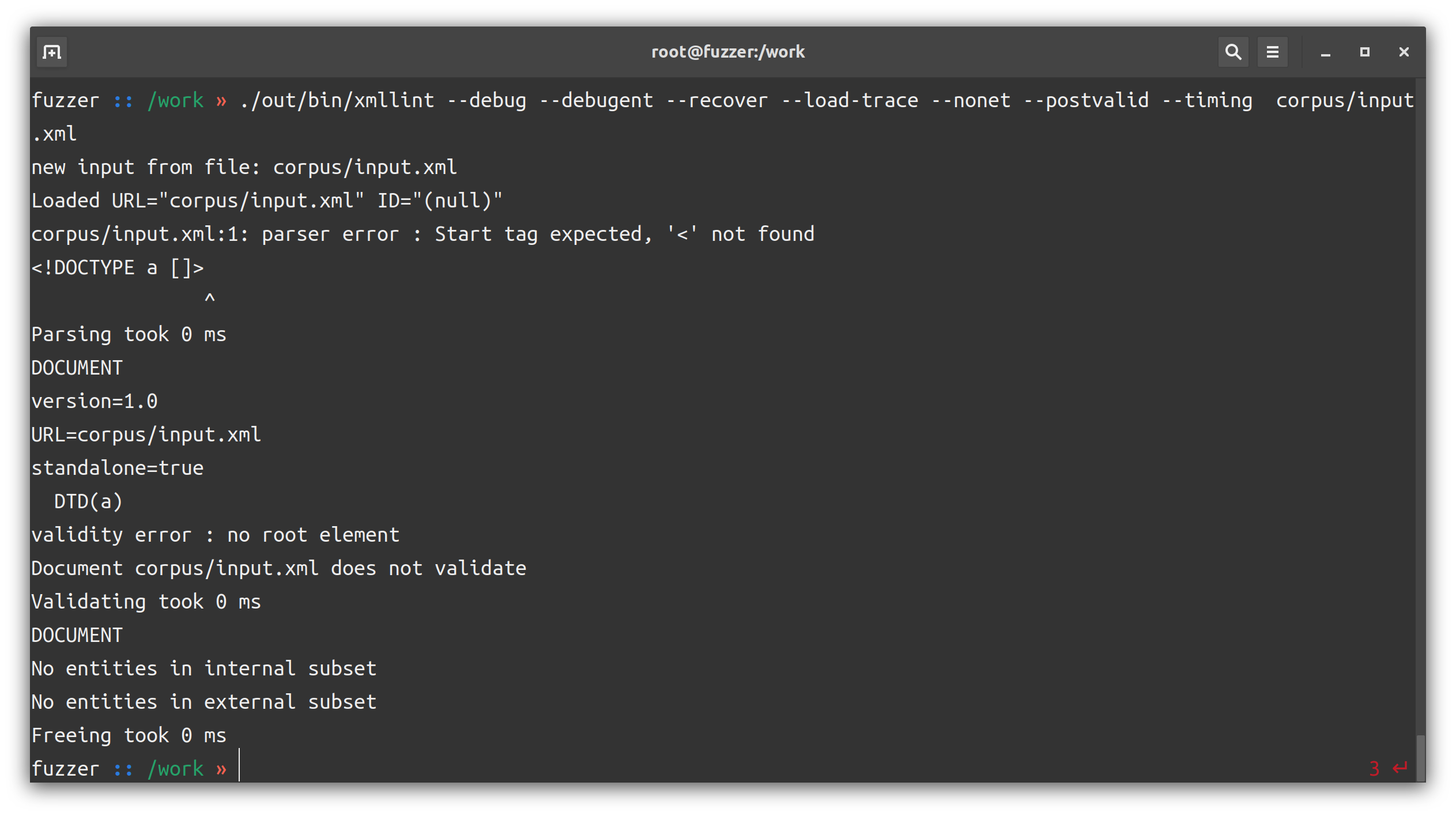
Usage : ./out/bin/xmllint [options] XMLfiles ...
Parse the XML files and output the result of the parsing
--version : display the version of the XML library used
--debug : dump a debug tree of the in-memory document
--shell : run a navigating shell
--debugent : debug the entities defined in the document
--copy : used to test the internal copy implementation
--recover : output what was parsable on broken XML documents
--huge : remove any internal arbitrary parser limits
--noent : substitute entity references by their value
--noenc : ignore any encoding specified inside the document
--noout : don't output the result tree
--path 'paths': provide a set of paths for resources
--load-trace : print trace of all external entities loaded
--nonet : refuse to fetch DTDs or entities over network
--nocompact : do not generate compact text nodes
--htmlout : output results as HTML
--nowrap : do not put HTML doc wrapper
--valid : validate the document in addition to std well-formed check
--postvalid : do a posteriori validation, i.e after parsing
--dtdvalid URL : do a posteriori validation against a given DTD
--dtdvalidfpi FPI : same but name the DTD with a Public Identifier
--timing : print some timings
--output file or -o file: save to a given file
--repeat : repeat 100 times, for timing or profiling
--insert : ad-hoc test for valid insertions
--compress : turn on gzip compression of output
--html : use the HTML parser
--xmlout : force to use the XML serializer when using --html
--nodefdtd : do not default HTML doctype
--push : use the push mode of the parser
--pushsmall : use the push mode of the parser using tiny increments
--memory : parse from memory
--maxmem nbbytes : limits memory allocation to nbbytes bytes
--nowarning : do not emit warnings from parser/validator
--noblanks : drop (ignorable?) blanks spaces
--nocdata : replace cdata section with text nodes
--format : reformat/reindent the output
--encode encoding : output in the given encoding
--dropdtd : remove the DOCTYPE of the input docs
--pretty STYLE : pretty-print in a particular style
0 Do not pretty print
1 Format the XML content, as --format
2 Add whitespace inside tags, preserving content
--c14n : save in W3C canonical format v1.0 (with comments)
--c14n11 : save in W3C canonical format v1.1 (with comments)
--exc-c14n : save in W3C exclusive canonical format (with comments)
--nsclean : remove redundant namespace declarations
--testIO : test user I/O support
--catalogs : use SGML catalogs from $SGML_CATALOG_FILES
otherwise XML Catalogs starting from
file:///etc/xml/catalog are activated by default
--nocatalogs: deactivate all catalogs
--auto : generate a small doc on the fly
--xinclude : do XInclude processing
--noxincludenode : same but do not generate XInclude nodes
--nofixup-base-uris : do not fixup xml:base uris
--loaddtd : fetch external DTD
--dtdattr : loaddtd + populate the tree with inherited attributes
--stream : use the streaming interface to process very large files
--walker : create a reader and walk though the resulting doc
--pattern pattern_value : test the pattern support
--chkregister : verify the node registration code
--relaxng schema : do RelaxNG validation against the schema
--schema schema : do validation against the WXS schema
--schematron schema : do validation against a schematron
--sax1: use the old SAX1 interfaces for processing
--sax: do not build a tree but work just at the SAX level
--oldxml10: use XML-1.0 parsing rules before the 5th edition
--xpath expr: evaluate the XPath expression, imply --noout
Libxml project home page: http://xmlsoft.org/
To report bugs or get some help check: http://xmlsoft.org/bugs.html
我们这里打开 --debug --debugent --recover --load-trace --nonet --postvalid --timing 开关。
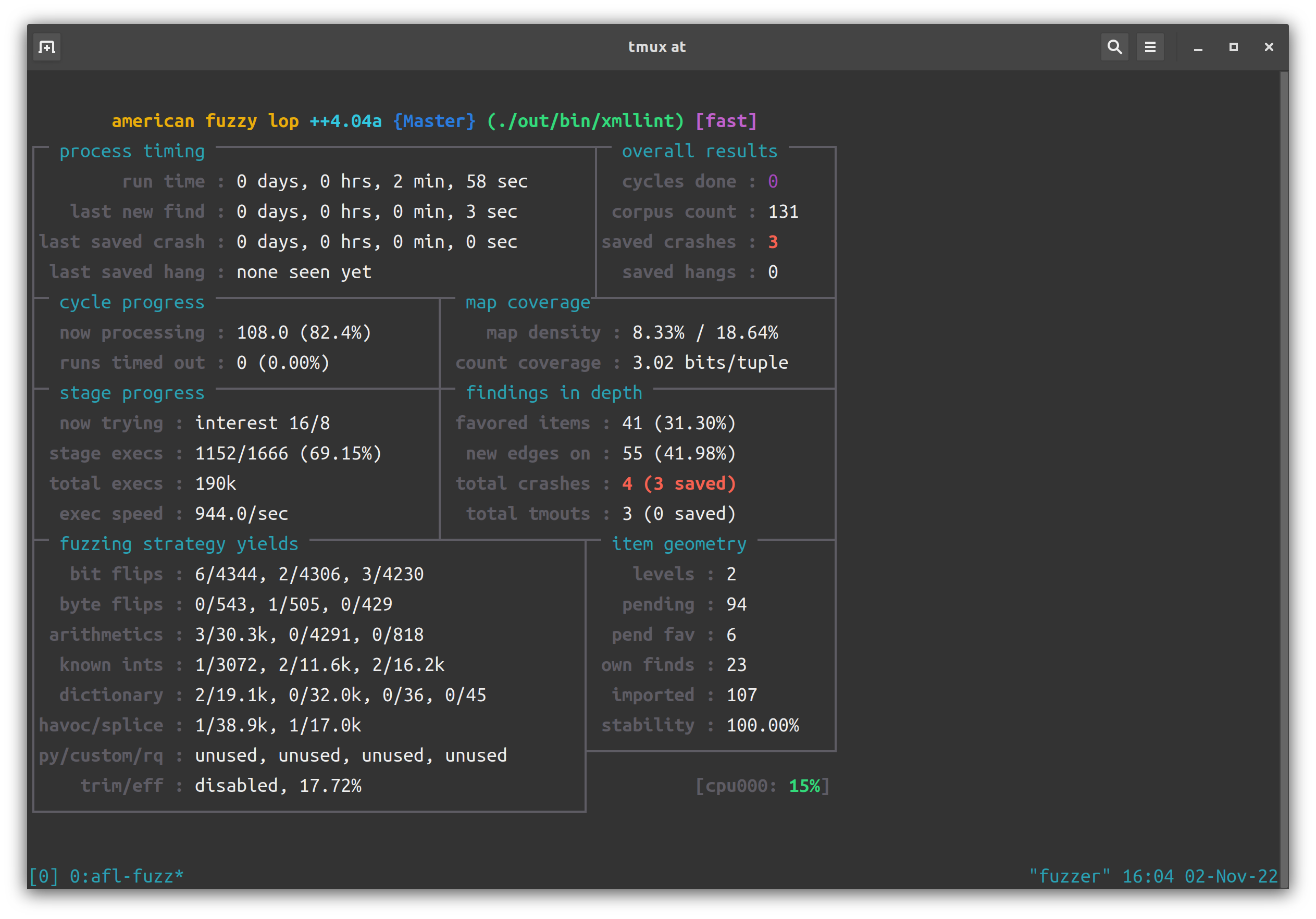
开始并行 fuzz:
/afl/afl-fuzz -i /work/corpus -x /work/dict/xml.dict -o /work/sync -D -M Master -- ./out/bin/xmllint --debug --debugent --recover --load-trace --nonet --postvalid --timing @@
/afl/afl-fuzz -i /work/corpus -x /work/dict/xml.dict -o /work/sync -S slave1 -- ./out/bin/xmllint --debug --debugent --recover --load-trace --nonet --postvalid --timing @@
/afl/afl-fuzz -i /work/corpus -x /work/dict/xml.dict -o /work/sync -S slave2 -- ./out/bin/xmllint --debug --debugent --recover --load-trace --nonet --postvalid --timing @@
/afl/afl-fuzz -i /work/corpus -x /work/dict/xml.dict -o /work/sync -S slave3 -- ./out/bin/xmllint --debug --debugent --recover --load-trace --nonet --postvalid --timing @@crash 出得非常快。