

0x00 起因
读者应该已经熟悉各种各样的 uptime bot。这些 bot 定期执行任务(例如 ping 一下服务器、看一眼首页的 HTTP 状态码是否为 200),生成日志,于是我们便可以知道在过去几天内,服务器 down 机的时间有多长。这类应用的典型代表是 louislam/uptime-kuma。
而笔者面临的任务,比单纯的 uptime 稍稍复杂一些。简而言之,笔者手上有若干台服务器,上面运行着各种业务;笔者需要定期检查这些业务是否正常,指标包含 web 服务是否可以正常使用、内存及磁盘占用等。本文将这样的日常检查称为“巡检”。一场巡检可能包含:
- 用浏览器打开网站,登录账号,进入各个页面,观察是否正常
- ssh 连接服务器,运行 htop 等指令
- 编写巡检报告
一位工作人员可能需要巡检多台服务器,如果人工执行所有巡检步骤,对工作者而言无异于体力劳动。另一方面,巡检员直接用 ssh 登录服务器,存在误操作的风险;巡检报告中的一些字段(例如日期)也容易误填。于是,我们有必要实现一个自动巡检系统。
0x01 基础工具:利用 pexpect 实现 ssh 自动化
显然,欲实现自动巡检,则必须先能自动化控制 ssh 和浏览器。我们先来讨论 ssh。第一种方案是建立 ssh 信道向服务端传输指令,有现成的 paramiko 库可以使用;第二种方案是在本机执行 ssh user@ip 指令,然后我们与 ssh 进程进行本地通讯。此方案可以使用 pexpect 库实现。
考虑到方案二的可扩展性优于方案一(不仅能支持 ssh,也能支持其他命令行程序),我们选择了 pexpect。使用方法是:启动一个进程,等待它发来某个字符串,然后发送我们的 payload,如此循环,直到完成任务。举个例子,假设我们想要调用 passwd 工具修改密码,则需要先输入旧密码,再输入两次新密码:

使用 pexpect,我们的工作流程就是:启动 passwd 进程,等待出现 Current password: 字符串,然后发送旧密码;等待出现 New password: 字符串,发送新密码;等待出现 Retype new password:,再次发送新密码。代码如下:
import pexpect
io = pexpect.spawn('passwd')
io.expect('Current password:')
io.sendline('-----------')
io.expect('New password:')
io.sendline('***********')
io.expect('Retype new password:')
io.sendline('***********')
print(io.read())
# b' \r\npasswd: password updated successfully\r\n'回顾 ssh 密码登录流程。服务器会发来 xxx's password: 字符串,在此之后我们输入密码,进入服务器的 shell。
因此,假设我们想要在服务器上执行 df -h 查看磁盘占用,我们只需写出以下代码:
import pexpect
import os
io = pexpect.spawn(
'ssh neko@192.168.8.200',
logfile=open('log', 'wb')
)
io.expect_exact('password:')
io.sendline(os.environ['PASSWD'])
io.expect_exact('$')
io.sendline('df -h')
io.expect_exact('$')
print(io.before, io.after)
# b' df -h\r\n\x1b[?2004l\rFilesystem Size Used Avail Use% Mounted on\r\nudev 7.8G 0 7.8G 0% /dev\r\ntmpfs 1.6G 744K 1.6G 1% /run\r\n/dev/sda1 294G 1.5G 277G 1% /\r\ntmpfs 7.9G 0 7.9G 0% /dev/shm\r\ntmpfs 5.0M 0 5.0M 0% /run/lock\r\ntmpfs 1.6G 0 1.6G 0% /run/user/1000\r\n\x1b[?2004h\x1b]0;neko@center: ~\x07\x1b[01;32mneko@center\x1b[00m:\x1b[01;34m~\x1b[00m' b'$'提供 logfile 参数之后,pexpect 会将通讯字节流写入日志文件,很方便调试。代码中采用了 io.expect_exact() 方法而非 io.expect(),因为后者匹配的是正则表达式,前者是直接匹配字符串。当匹配完成之后,我们可以读取 io.before 获得匹配前的字符串,读取 io.after 获得匹配之后的字符串。
不过,我们发现,读出的字符串里面包含有一些特殊字符。这些是 ANSI escape code,可以用于实现文本颜色等功能,详情可见 Burke Libbey 的一篇文章。我们之后使用 htop 等指令时,服务器还会发来更多的控制字符。我们需要模拟出一个终端,吞进这些字节流,然后渲染出界面——每个位置是哪个字符、是什么颜色。有 selectel/pyte 库可以用于此项工作。
print 出这些控制字符,屏幕上也能显示正确的渲染结果。这可以帮助判断截取的字节流是否合适。io.interact() 使 pexpect 进入交互状态,这也是调试利器。行为类似于 pwntools 的 io.interactive()。0x02 基础工具:利用 pyte 解析 ANSI 字节流
pyte 的使用方法是:建立一个指定尺寸的虚拟终端;喂进字节流;读取虚拟终端的状态。基础代码:
import pyte
term = pyte.Screen(120, 80)
stream = pyte.Stream(term)
raw_bytes = b' df -h\r\n\x1b[?2004l\rFilesystem Size Used Avail Use% Mounted on\r\nudev 7.8G 0 7.8G 0% /dev\r\ntmpfs 1.6G 744K 1.6G 1% /run\r\n/dev/sda1 294G 1.5G 277G 1% /\r\ntmpfs 7.9G 0 7.9G 0% /dev/shm\r\ntmpfs 5.0M 0 5.0M 0% /run/lock\r\ntmpfs 1.6G 0 1.6G 0% /run/user/1000\r\n\x1b[?2004h\x1b]0;neko@center: ~\x07\x1b[01;32mneko@center\x1b[00m:\x1b[01;34m~\x1b[00m'
stream.feed(raw_bytes.decode())
print('\n'.join(term.display))运行结果:
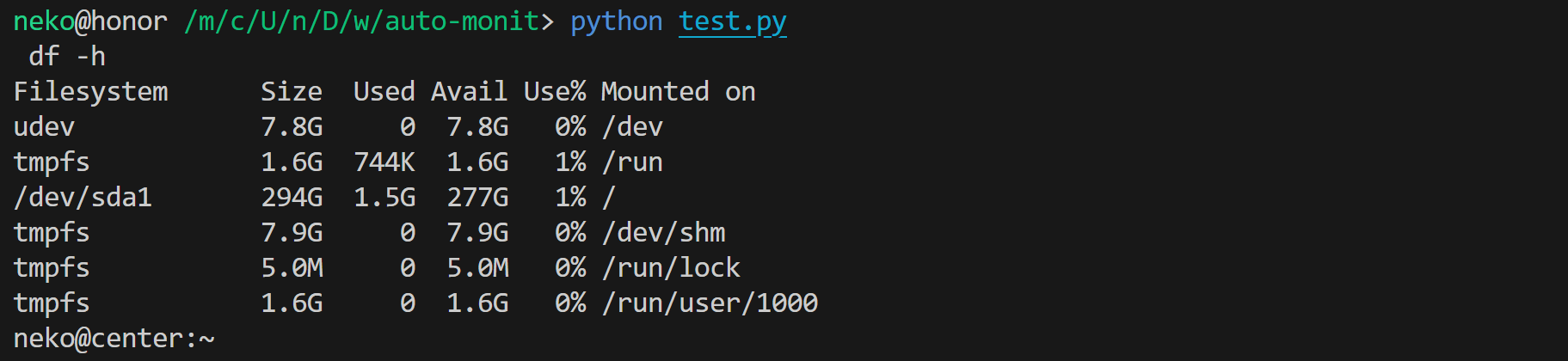
我们这里使用 term.display 直接读出字符串,丢失了颜色信息。想获取前景色、背景色、是否加粗等信息,可以使用 term.buffer。
print(term.buffer[0][0])
# Char(data=' ', fg='default', bg='default', bold=False, italics=False, underscore=False, strikethrough=False, reverse=False)我们可以从 term.buffer 生成带颜色标签的 html,代码如下:
def ansi_raw_to_html(s):
screen = pyte.Screen(n_cols, n_rows)
stream = pyte.Stream(screen)
if type(s) == bytes:
s = s.decode("utf8")
stream.feed(s)
buf = ""
def get_classes(c):
classes = []
for key in [
"fg",
"bg",
"bold",
"italics",
"underscore",
"strikethrough",
"reverse",
]:
val = getattr(c, key)
match val:
case str():
if val != "default":
classes.append(f"{key}-{val}")
case bool():
if val:
classes.append(key)
return " ".join(classes)
for x in range(n_rows):
t = []
for y in range(n_cols):
a = screen.buffer[x][y]
cs = get_classes(a)
t.append((cs, html.escape(a.data)))
buf += '<div class="term-line">'
for cs, chars in itertools.groupby(t, key=lambda z: z[0]):
buf += '<code class="{}">{}</code>'.format(
cs, "".join(map(lambda z: z[1], chars))
)
buf += "</div>"
empty_line = f'<div class="term-line"><code class="">{" " * n_cols}</code></div>'
while buf.startswith(empty_line):
buf = buf[len(empty_line) :]
while buf.endswith(empty_line):
buf = buf[: -len(empty_line)]
buf = '<pre class="term-block">' + buf + "</pre>"
r = jinja2.Template(
open(os.path.join("share", "base.html"), encoding="utf8").read()
).render(body=buf)
with open(os.path.join("tmp", "term.html"), "w", encoding="utf8") as f:
f.write(r)
return buf模板文件 base.html 如下:
<!DOCTYPE html>
<html lang="en">
<head>
<style>
body{
font-family: 'Sarasa Fixed SC';
}
pre, code{
font-family: 'Sarasa Fixed SC';
font-size: 14px;
}
.term-block{
background-color: #eeeeee;
margin: 0 0 4px 0;
padding: 2px;
border: 1px solid #dddddd;
}
.fg-black{color: black;}
.fg-red{color: rgba(255, 0, 0, 70%);}
.fg-green{color: green;}
.fg-brown{color: brown;}
.fg-blue{color: blue;}
.fg-magenta{color: magenta;}
.fg-cyan{color: hsl(198, 99%, 37%);}
.fg-white{color: gray;}
.fg-default{color: black;}
.bg-black{background-color: black;}
.bg-red{background-color: red;}
.bg-green{background-color: hsl(0.3turn 60% 45% / .7);}
.bg-brown{background-color: brown;}
.bg-blue{background-color: blue;}
.bg-magenta{background-color: magenta;}
.bg-cyan{background-color: hsl(198, 99%, 90%);}
.bg-white{background-color: gray;}
.bg-default{background-color: white;}
</style>
</head>
<body>
{% block body %}
{{body}}
{% endblock %}
</body>
</html>效果:

使用 wkhtmltopdf 生成 PDF 文件:
wkhtmltopdf --encoding utf8 --page-width 260mm --page-height 4500mm report.html out.pdf至此,我们已经实现“通过 ssh 自动发送指令,并渲染出带颜色的 html”。ssh 巡检的自动化已经基本完成,接下来考虑浏览器的自动化。
0x03 基础工具:利用 selenium 实现浏览器自动化
本站四年前的文章已经使用过 selenium,今次继续用它实现浏览器巡检。写代码的过程没有多少好说,不过有几个坑点需要注意:
不宜使用 sleep(10) 等待页面加载。影响页面加载速度的因素非常多,例如电脑的性能、网速、有否静态文件缓存等。强行指定等待时间,很容易在页面未加载完成的情况下便进行下一步操作;若等待时间设置过长,则造成浪费。合理的方案是轮询某个条件,例如:
def wait_for_web(b):
time.sleep(2)
while "Loading" in b.page_source:
time.sleep(1)
time.sleep(2)若页面上有 iframe,则 b.find_element 无法直接定位到 iframe 内部的 DOM。需要先切换到特定的 iframe:
iframe = b.find_element(
By.CSS_SELECTOR,
"iframe[src='/page/aloha/oe']",
)
b.switch_to.frame(iframe)新版 selenium 比起当年的版本,引入了 Selenium Manager 工具,以管理各种 driver。这个工具对局域网环境极不友好,我们有必要禁用之,转而使用自己提供的 driver。写法如下:
os.environ["SE_OFFLINE"] = "true"
gecko_path = os.environ['GECKODRIVER_PATH']
arg = {}
if gecko_path:
arg['executable_path'] = gecko_path
service = webdriver.FirefoxService(**arg)
self.browser = webdriver.Firefox(service=service)- 在 wsl 里面跑 ssh 巡检,在 Windows 跑浏览器巡检,需要代码做好隔离,不要产生 import 错误
- 使用带桌面的 Linux 系统
- 高版本的 wsl 2 可以提供图形界面,见微软的文档 (这是笔者最后采取的方案)
0x04 敏捷开发
笔者一边研究 pexpect 等工具的使用,一边编写了原型系统。项目组织上,将普遍可复用的代码(例如从 ANSI 字节流渲染 html)放进了 util 目录,然后每个系统各自实现一遍巡检业务逻辑。目录结构大致是:
.
├── 1-clean.cmd
├── 2-go-A.cmd
├── 3-go-B.cmd
├── 4-gen-report.cmd
├── autoins_A1-1.py
├── autoins_A1-2.py
├── autoins_A2-1.py
├── autoins_A2-2.py
├── autoins_B1-1.py
├── autoins_B1-2.py
├── autoins_B2-1.py
├── autoins_B2-2.py
├── clean.py
├── gen_A_report.py
├── gen_B_report.py
├── template
│ └── base.html
├── util
│ ├── db.py
│ └── term.py
├── wkhtmltopdf.exe
└── worklog.db然而,我们存在这样的情况:两台服务器上部署了相同的应用,它们 IP 不一致,密码不一致,而且由于版本不同,可能流程上有细微差别。在原型系统中,笔者先开发了 X 系统的巡检逻辑,然后将其复制出来,修改出 Y 系统的巡检代码。最终,两份代码的大部分都是相同的。这样的做法违反了设计模式(Don't repeat yourself),很不适合维护。我们需要重新设计自动巡检系统。
0x05 新的设计
让我们回想一次 ssh 巡检流程:
- 登录 ssh(在不同的业务系统中,IP、端口、密码等参数不同)
- 执行
df -h - 执行
htop - 执行其他指令(每个业务系统有各自的特殊指令要执行)
而一次典型的浏览器巡检流程如下:
- 登录(各个系统登录逻辑不同),截图
- 进入 A 页面,截图
- 进入 B 页面,执行某操作,截图
我们可以发现,巡检可以拆分成不同的步骤(Step),例如“执行 df -h”就是一个步骤。步骤的序列构成了巡检过程,我们只需要拼接各种步骤,形成步骤链(WorkChain),就可以完全描述一场巡检。而步骤的可复用性很高,以“执行 df -h”这个步骤为例,我们只需要向 ssh 进程发送一句 df -h,然后等待出现 $ 符号或 # 符号(这代表着 df 已经执行完毕,shell 发回了形如 neko@lab:~$ 的字符串,等待下一条指令)。我们只需要实现一次 df -h 步骤,就能在所有的 ssh 巡检中使用之。更进一步地,我们可以实现通用的“执行终端指令”步骤,从这个通用步骤派生出 df -h、uname -a 等各种详细步骤。
于是,我们应该会有这样的代码:
class StepCommand(Step):
def __init__(self, cmd, shell_prompt):
# ...
def exec(self):
# ...
class StepLogin(Step):
# ...
class StepDf(StepCommand):
def __init__(self, shell_prompt):
super().__init__('df -h', shell_prompt)
class StepUname(StepCommand):
def __init__(self, shell_prompt):
super().__init__('uname -a', shell_prompt)
c = WorkChain("测试链")
c.step(StepLogin('$'))
c.step(StepDf('$'))
c.step(StepUname('$'))
c.work()这份代码有两个问题。首先,StepCommand 的 exec 方法是需要有 pexpect 对象的,而这个对象由 StepLogin 产生。我们不宜将 pexpect 对象放进全局变量,所以应当在 WorkChain 对象中维护一个 context,它是一个 map,专门用于存放与此 WorkChain 相关的各种对象。显然,shell_prompt 也可以放进 context,于是我们就只需在 StepLogin 步骤提供 shell_prompt ,而无需在每次实例化 StepDf 等步骤时都提供一遍。
另一个问题在于,有些步骤打开了资源,我们需要在合适的时机予以关闭。例如,StartBrowser 步骤会打开浏览器,按照目前的设计,我们需要再实现一个 CloseBrowser 步骤,在巡检的最后时刻执行,以关掉浏览器。我们分别实现开启、关闭两个步骤是不雅观的,如果我们手上的资源很多(例如在某次巡检中同时打开 3 个浏览器和 2 个 ssh),会造成不便。因此,我们提出 Resource 类,它在巡检之初执行 init() 方法,在巡检结束时执行 close() 方法。
最终,我们一套巡检逻辑的代码如下:
c = WorkChain("ssh测试链")
c.resource(
"ssh",
RemoteTerminal(["user@host"], os.environ["PWD_TEST"],shell_prompt="$")
)
# 此后可以通过 c.res['ssh'] 访问到 RemoteTerminal 对象
c.step(StepCommand("cat /etc/issue"))
c.step(StepCommand("ps aux"))
c.step(StepCommand("screenfetch"))
c.step(StepHtop())
c.work()IPython.embed() 进入 IPython 交互环境,这对于 selenium 非常有用。