

前六篇文章中,我们已经读完了 AFL 的源码。本文是这个系列的完结篇,从一个 fuzzing 研究者的角度,讨论我们应该如何在 AFL 基础上二次开发。本文要达成三个目标:
- 目标一:统计测试用例长度随时间的变化趋势
- 目标二:给 havoc 阶段添加新的变异算子
- 目标三:追踪
virgin_bits的完成度
统计测试用例长度
我们想观察,AFL 变异出的那些测试用例,其长度在 fuzz 过程中如何变化。要达成这个目标,无需修改 AFL 本身。我们在第六篇文章中提到过,在 common_fuzz_stuff 函数中,fuzzer 生成的用例会经过后处理,再送给目标程序:
if (post_handler) {
// 前一篇文章提到过的 post handler 的调用位置
out_buf = post_handler(out_buf, &len);
if (!out_buf || !len) return 0;
} 而这个 post_handler 是通过动态库引入的。如果用户想提供一个后处理算法,仅需将其写进 afl_postprocess 函数,并编译成动态库,通过 AFL_POST_LIBRARY 环境变量传递给 fuzzer。
于是,我们编写以下代码:
#include <stdio.h>
#include <stdint.h>
uint8_t* afl_postprocess(uint8_t* buf, uint32_t* len) {
// 取过去 100 次执行的平均值
static uint32_t len_sum, cnt;
len_sum += *len;
cnt++;
if(cnt == 100) {
puts("save avg length");
FILE* fp = fopen("/tmp/avg_len", "a");
fprintf(fp, "%lf\n", (double)(len_sum) / cnt);
fclose(fp);
len_sum = 0;
cnt = 0;
}
return buf;
}编译:
gcc -fPIC -shared work.c -o mypost.so这样就拿到了动态库,将其提供给 afl-fuzz 即可。现在来做一个实验。我们以一个简单的程序为目标:
#include <stdio.h>
#include <unistd.h>
int main(void) {
char s[150];
read(0, s, 400);
int len = -1;
do {
len++;
} while(s[len] == 'a');
printf("%d\n", len);
return 0;
}
// 编译指令:AFL_DONT_OPTIMIZE=1 ../afl-gcc app.c -o app -g运行 fuzzer:
AFL_NO_UI=1 AFL_POST_LIBRARY=./mypost.so ../afl-fuzz -i ./corpus -o ./work -- ./app 于是,就可以从 /tmp/avg_len 里面读到数据了:
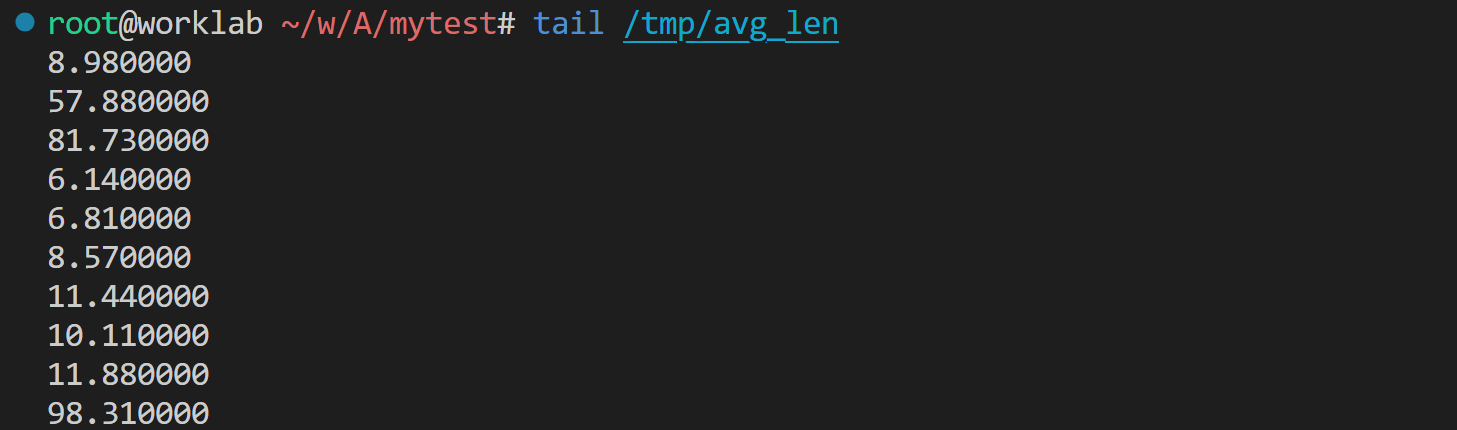
用 Python 做个可视化。
import numpy as np
import matplotlib.pyplot as plt
with open('avg_len') as f:
data = f.readlines()
data = [float(x) for x in data][:1500]
plt.xlabel('exec/100')
plt.ylabel('avg len')
plt.plot(range(len(data)), data)
plt.show()结果如下:
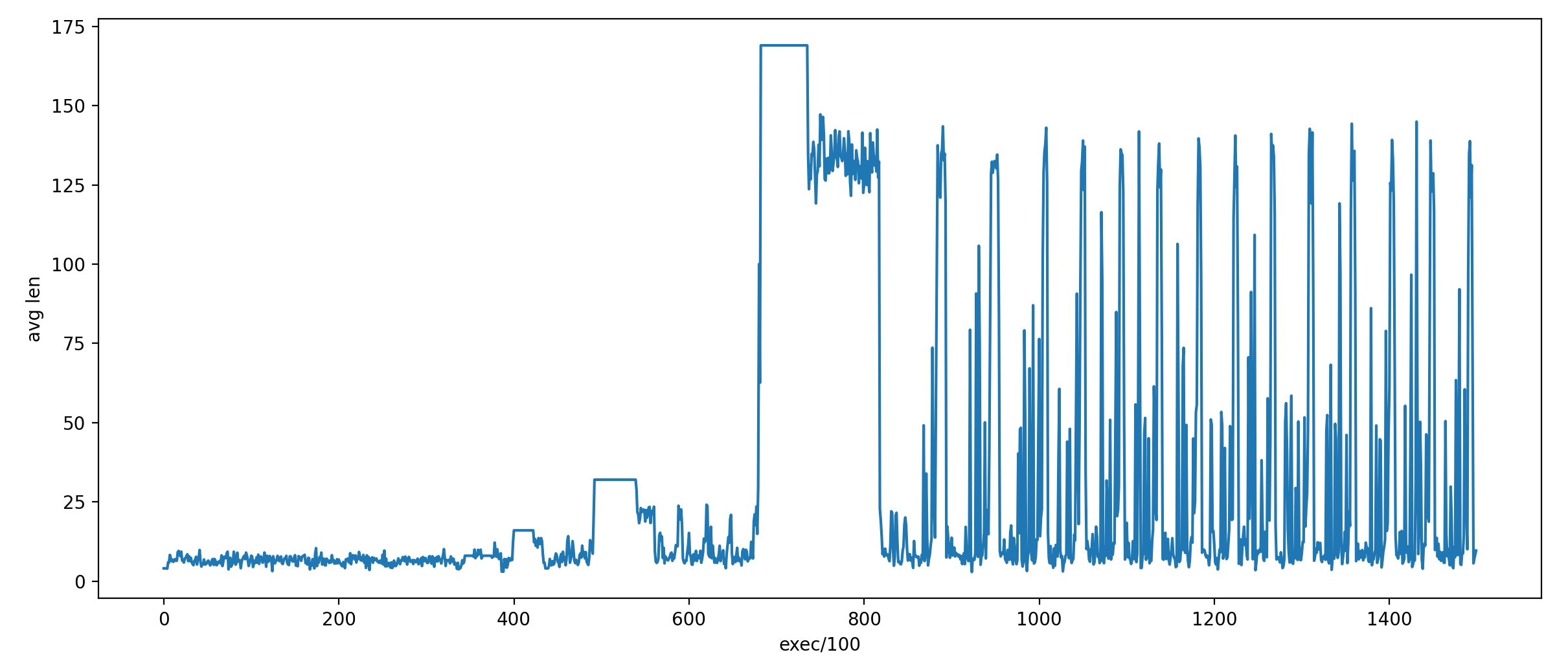
可以发现,程序在运行初期,由于初始用例很小,变异出的用例也很小;某一次发现了以 16 个 a 开头的有趣用例,将其入队后,在其基础上进行了一些变异,其 deterministic 变异阶段在图中产生了一个小台阶;图中纵轴为 32 的台阶也是这样产生的。当变异出长度超过 150 的用例以后,程序由于栈溢出,出现了其他行为,因此该用例被视为有趣,并加以 fuzz。这产生了纵轴为 169 的那个台阶。
在此之后,程序循环 fuzz 队列中的各个用例,因此图中的后半部分是一个个峰。
添加变异算子
有许多论文给 havoc 阶段添加自定义的算子。例如 EMS 定义了这样一个算子:按照历史经验,把某个特定字符串替换为另外的特定字符串。除此之外,havoc 阶段如何选择变异算子、变异位置,也是研究的热点之一。
我们知道,原始 AFL 不太可能通过 magic number 检查(如果 corpus 中没有出现过的话)。来写一个简单的程序:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
static unsigned int a[10];
read(0, &a, 40);
if(a[0] == 0xcafe1234)
if(a[7] == 0xbabe5678)
abort();
}
// 编译指令:AFL_DONT_OPTIMIZE=1 ../../afl-gcc magic.c -o magic -g 初始语料集设为 "haha"。那么,原始 AFL 显然没法让这个程序 crash,因为 0xcafe1234 和 0xbabe5678 这两个 magic number 并不在字典中。不过,我们可以给 AFL 添加两个变异算子——负责把用例中的随机 dword 替换成 0xcafe1234 和 0xbabe5678。显然,如果 havoc 阶段有了这两个算子,AFL 马上就能变异出 crash 用例。
首先修改 havoc 选择变异算子的那个 switch:
stage_cur_val = use_stacking;
for (i = 0; i < use_stacking; i++) {
// 添加两个算子
switch (UR(15 + 2 + ((extras_cnt + a_extras_cnt) ? 2 : 0))) {
case 0:
/* Flip a single bit somewhere. Spooky! */AFL 自带的 havoc 变异算子(编号 0 - 16)中,最后两个算子(15、16)是在有词典可用的情况下,才会被选取。因此,我们把自己的新算子放在 15、16 这两个位置,而把词典相关的算子挪到 17、18。修改后的代码如下:
case 15: {
// 我们添加的第一个算子,负责随便找个 dword 替换成 0xcafe1234
// 若输入长度不够,则跳过
if (temp_len < 4) break;
// 找一个合适的位置
u32 pos = UR(temp_len - 3);
*(u32*)(out_buf + pos) = 0xcafe1234;
break;
}
case 16: {
// 我们添加的第二个算子,负责随便找个 dword 替换成 0xbabe5678
// 若输入长度不够,则跳过
if (temp_len < 4) break;
// 找一个合适的位置
u32 pos = UR(temp_len - 3);
*(u32*)(out_buf + pos) = 0xbabe5678;
break;
}
// 以下是 AFL 自带的词典相关算子,将其挪到 17、18
/* Values 15 and 16 can be selected only if there are any extras
present in the dictionaries. */
case 17: {
/* Overwrite bytes with an extra. */
重新编译 AFL:
make clean
make运行:
AFL_NO_UI=1 ./afl-fuzz -i ./mytest/magic/corpus -o ./mytest/magic/work -- ./mytest/magic/magic果然找到了 crash:
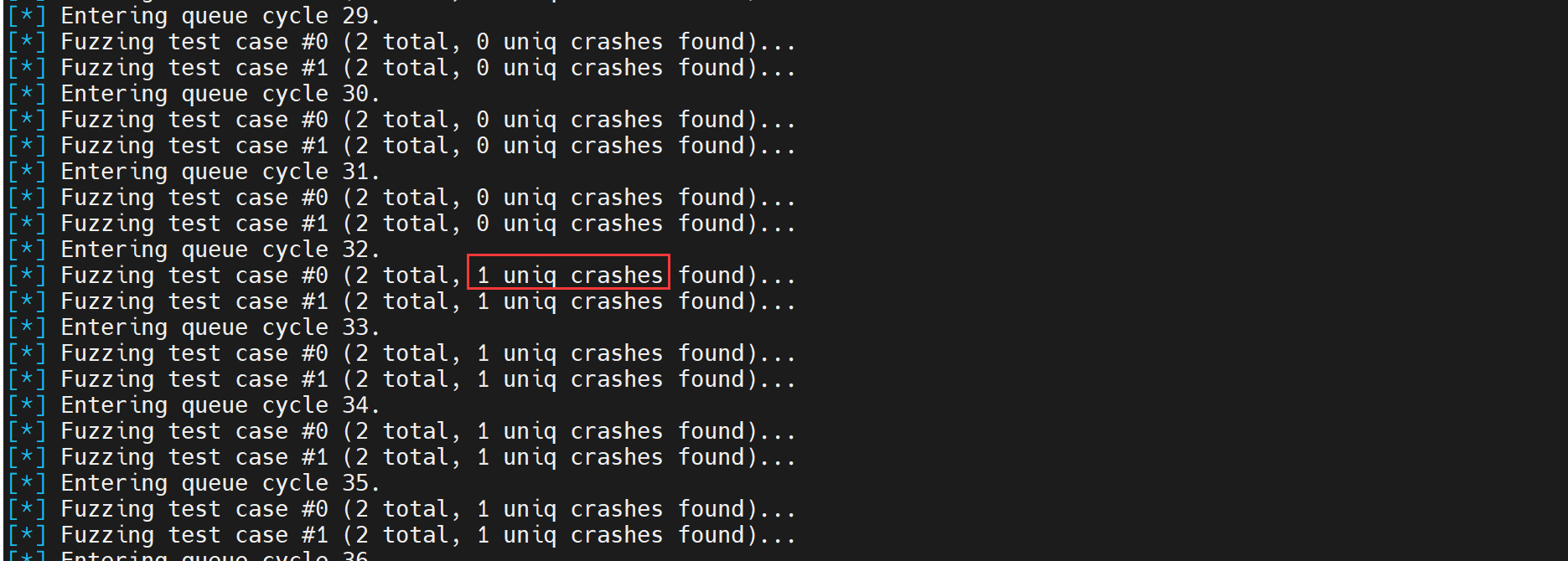

可见我们的变异算子确实被 AFL 使用了。
追踪 virgin_bits
上一篇文章提到,AFL 运行过程中,如果发现一个用例完成了 virgin_bits 中还未被达成过的任务(这样的任务共有 524288 个),则这个用例会被保留进 queue。显然,virgin_bits 的变化过程,可以提示 fuzzer 对目标程序的探索进度。
AFL 会定期把 virgin_bits 写进 fuzz_bitmap 文件,但我们希望在每次发现有趣用例时,都保存下来当时的 virgin_bits。因此,我们去修改 afl-fuzz.c 中的 save_if_interesting 函数:
// ...
// 如果没发现新的路径,就忽略
// has_new_bits 返回值:0 表示无成果;1 表示 hit count 变动;2 表示发现了新的边
if (!(hnb = has_new_bits(virgin_bits))) {
if (crash_mode) total_crashes++;
return 0;
}
// ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
// 这里产生了 virgin_bits 的更新,因此把现在的 virgin_bits 保存进文件
{
printf("save virgin bits for id %06u\n", queued_paths);
u8* virgin_filename = alloc_printf("/tmp/virgin_bits/id:%06u,%s", queued_paths, describe_op(hnb));
FILE *virgin_fp = fopen(virgin_filename, "w");
fwrite(virgin_bits, 1, sizeof(virgin_bits), virgin_fp);
fclose(virgin_fp);
ck_free(virgin_filename);
}
// ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
// 发现了新的路径,要将其加入 queue 并存到文件中
#ifndef SIMPLE_FILES
// 这是用例的文件名,描述了 id、来历
fn = alloc_printf("%s/queue/id:%06u,%s", out_dir, queued_paths,
describe_op(hnb));
// ... 我们把储存 virgin_bits 的代码添加到 AFL 原有的「把一个有趣用例保存进文件系统」之前。virgin map 会被保存到 /tmp/virgin_bits 目录下,命名规则与 AFL 保持一致。
save_if_interesting 函数,故初始用例的 virgin map 不会被保存。如果想要把初始 corpus 的 virgin map 也保存下来,可以改为在 add_to_queue 函数添加代码。现在,找个真实世界程序来验证一下。我们选择此前 fuzz 过的 xpdf 来做这个实验。先插桩编译目标程序:
wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz
tar -zxvf xpdf-3.02.tar.gz
cd xpdf-3.02/
CC=/root/work/AFL-master/afl-gcc CXX=/root/work/AFL-master/afl-g++ ./configure --prefix="/root/fuzz/bin"
make
make install找一些初始 corpus:
wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
wget http://www.africau.edu/images/default/sample.pdf
wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf运行 fuzzer:
AFL_NO_UI=1 /root/work/AFL-master/afl-fuzz -i ./corpus/ -o ./work/ -- ./pdftotext @@ -可以看到,virgin map 被成功保存:
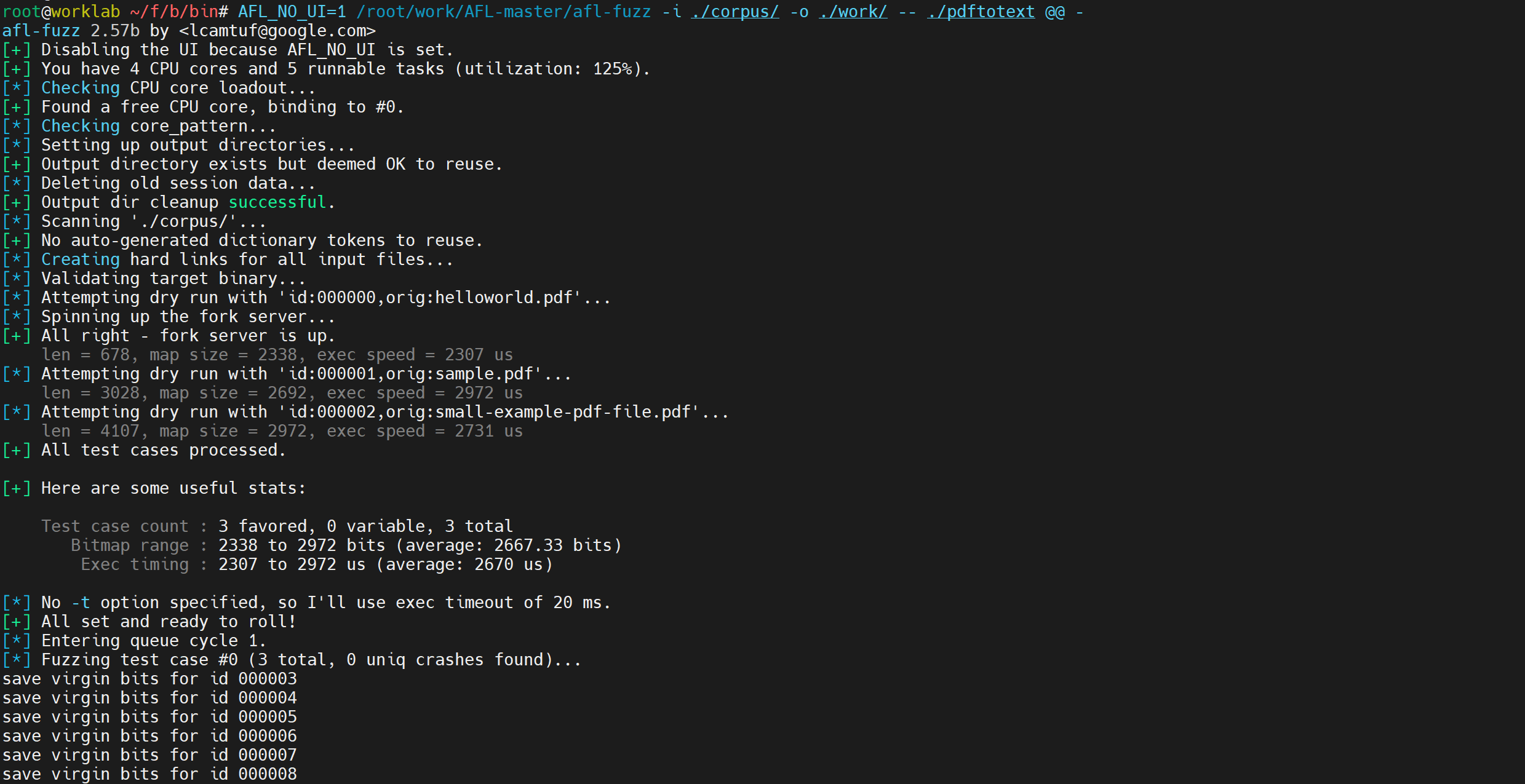
取出 /tmp 目录下的这些文件,写一个脚本展示 virgin map 随 fuzz 进度的变化。
import numpy as np
import os
import matplotlib.pyplot as plt
data = []
for name in sorted(os.listdir('bits/virgin_bits')):
with open(os.path.join('bits', 'virgin_bits', name), 'rb') as f:
data.append(list(f.read()))
data = np.array(data)
data = (data != 255)
map_touched = data.any(axis=0)
data = data[:, map_touched]
plt.xlabel('virgin map')
plt.imshow(data, cmap='Blues')
plt.show()结果如图:
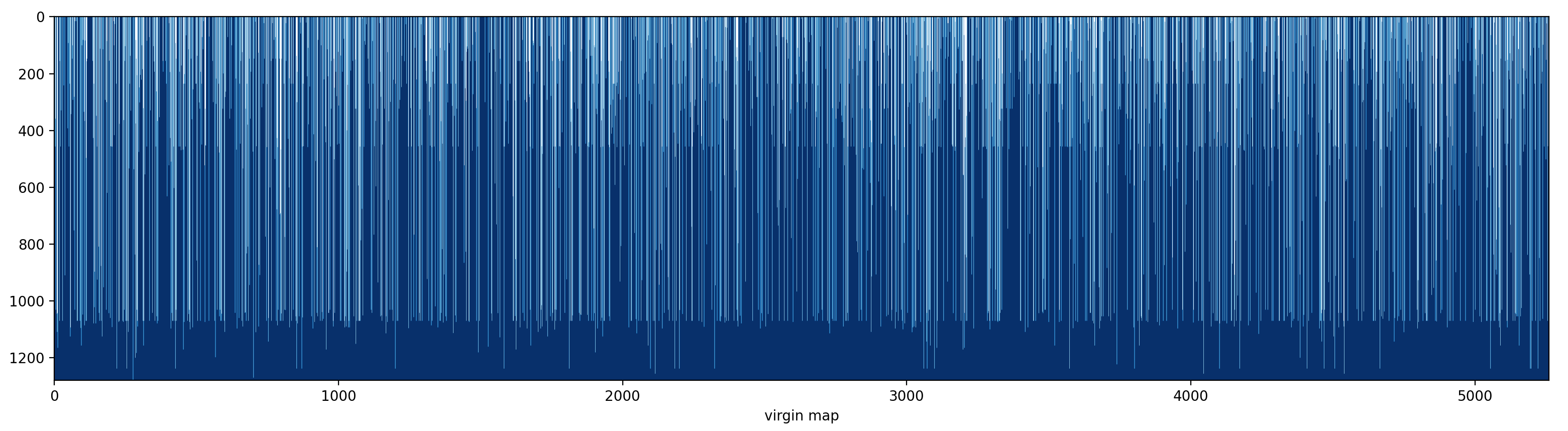
可以看到,这张图是分阶梯的:在纵轴大约 450 和 1100 处,有明显的分界。这说明,AFL 在这两个时间点变异出了超级用例,覆盖了许多未见过的边。研究者可以关注这些超级用例,以指导后续的 fuzz 过程。
《AFL 源码阅读》系列文章至此完结。感谢您的阅读,希望对您有帮助。
下面的附件是按照本文方法修改后的 AFL 源码,也包含此前阅读 AFL 源码过程中留下的注释。